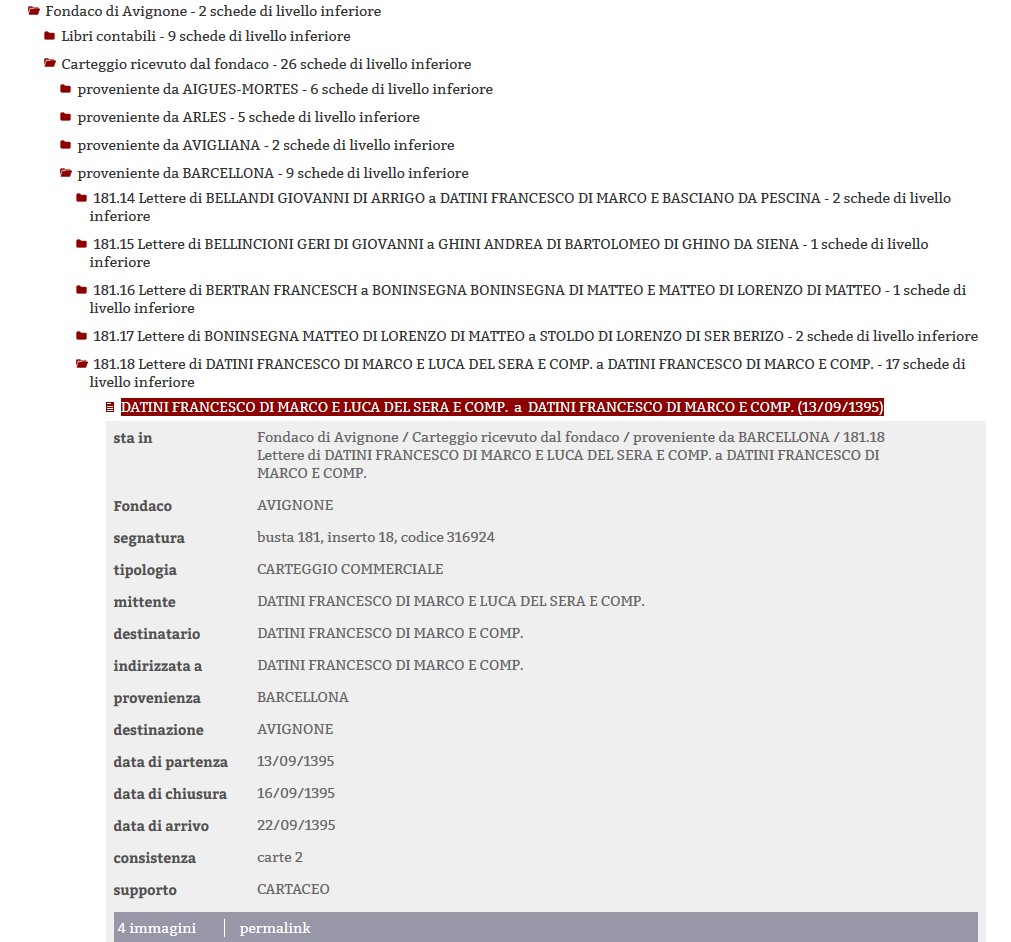
Figura 1- La descrizione di una lettera dal Fondo Datini dell'Archivio di Stato di Prato22
di Francesca Tomasi
I linked open data (LOD) sono ad oggi riconosciuti come strumento necessario alla valorizzazione semantica del cultural heritage. Il loro scopo è, fra gli altri, di agevolare l'interscambio fra risorse culturali e soddisfare i bisogni informativi del cosiddetto utente finale1. Oltre ad essere un modello tecnologico, i LOD rappresentano una nuova modalità di concepire la rappresentazione digitale dei dati culturali: non più data silos autoreferenziali, ma dati aperti e capaci di scambiare informazione e trasmettere conoscenza. Nel sistema archivi sono stati lanciati numerosi progetti di creazione di strumenti di corredo archivistico - o anche di descrizioni di complessi documentari e realizzazione di record di autorità per produttori e conservatori di archivi - in LOD. Uno per tutti, il lavoro condotto da ICAR (Istituto centrale per gli archivi) per il SAN (Sistema archivistico nazionale), nella creazione di Dati SAN LOD, un aggregatore di risorse prodotte da sistemi informativi e progetti locali e territoriali aderenti2.
Gli archivi di persona sono, in questa prospettiva, una singolarità, in quanto modello di riferimento importante per ripensare ai LOD come strumento di dialogo e interconnessione del sistema Galleries, Libraries, Archives and Museums (GLAM)3. Dalle collezioni documentarie prodotte da individui - in termini in particolare di persone, ma anche di enti e famiglie - è possibile costruire infatti reti di relazioni importanti, che trasformano le connessioni di primo livello, come per esempio i collegamenti ai sistemi di controllo di autorità, in connessioni di alto livello, cioè quelle che sfruttano tutte le capacità del Web attraverso l'interlinking con datasets LOD.
Gli archivi di persona e, in particolare, di personalità4, conservati presso istituzioni archivistiche, o donati alle biblioteche, rappresentano un'interessante prospettiva di studio perché sono portatori di un sapere che travalica i principi della descrizione archivistica per abbracciare i sistemi di descrizione dell'intero patrimonio culturale, rappresentato da documenti, ma anche da libri, artefatti o ancora risorse e oggetti, anche nativi digitali5, in un sistema di profonde interconnessioni spesso latenti.
Le ontologie rappresentano un passo determinante nella costruzione dei LOD. Anche se non esplicitamente compresi nel 5 stars di Tim Berners Lee6, i modelli concettuali sono capaci di fornire lo spessore semantico necessario a valorizzare la descrizione di dominio e a dare valore al link tipizzato, estendendo la rete delle interconnessioni attraverso collegamenti autoesplicativi.
Il lavoro condotto sull'archivio di Federico Zeri7, conservato presso la Fondazione che porta il nome dell'illustre critico, può essere un punto di partenza utile per ripensare al concetto di profondità della descrizione di oggetti culturali multiformi e di interlinking: tipologie documentarie eterogenee, relazioni fra persone, collegamenti fra l'archivio e la biblioteca, connessioni fra raccolta fotografica e opere d'arte riprodotte, dialogo dell'archivio con i cataloghi d'asta. L'archivio privato di Federico Zeri traduce dunque la problematicità sottesa ai LOD come strumento di interscambio in ottica GLAMs.
L'articolo intende dunque presentare il caso specifico degli archivi di persona per avviare una riflessione sul tema dei patrimoni documentari eterogenei e per ragionare sulle interconnessioni che nativamente tali collezioni veicolano, costringendo i sistemi di descrizione archivistici ad allargarsi verso i domini bibliografico e museale. Esplorando quindi il panorama degli standard di dominio si vuole introdurre il concetto di ontologia come strumento necessario alla creazione di basi di conoscenza (dati e modelli concettuali), esemplificando poi il percorso concettuale sul caso Zeri.
Le collezioni di persona, ovvero quelle carte che testimoniano le attività di un certo tipo di soggetto produttore nell'esercizio delle sue funzioni, rappresentano un'interessante specificità del patrimonio archivistico. Gli archivi di persona, e di personalità, sono spesso un fondo singolare, che unisce all'eterogeneità di unità documentarie la peculiarità di un sistema di relazioni multi livellari. In particolare, la documentazione prodotta da un individuo offre due interessanti prospettive di analisi: da un lato richiama l'esigenza di ordinare, descrivere, classificare e rendere fruibili materiali, ovvero documenti, che richiedono standard diversi ai diversi livelli della gestione del patrimonio (foto, appunti, lettere, ritagli di giornale, estratti, note e annotazioni, ma anche libri e periodici, artefatti e oggetti in generale); dall'altro costringe a riflettere sulla potenziale rete di relazioni che la persona, e la documentazione prodotta, sono in grado di intrattenere8.
Partiamo allora dal concetto di eterogeneità. Lo standard internazionale di descrizione del patrimonio archivistico, vale a dire ISAD9, offre un solido modello di metodologia descrittoria, su cui gli standard nazionali possono lavorare. Le linee guida per la realizzazione di strumenti di corredo archivistici10 traggono da ISAD il modello gerarchico che sovrintende al metodo. Ora l'attenzione dello standard è tutta orientata alla rappresentazione dei livelli della descrizione (semplificando: il fondo, la serie, il fascicolo, l'unità), assieme alla pertinenza della descrizione rispetto al livello, e solo piccola parte dedica al problema della definizione degli elementi atomici dell'unità documentaria, vale a dire dell'item. Il documento, come ultima catena di un inventario analitico (secondo le citate linee guida il livello C1) o come oggetto da descrivere svincolato dalla gerarchia (il livello C2), rimane un componente, ovvero un'entità, da descrivere a livello meta-informativo. Ora è evidente che il principio della descrizione archivistica focalizza sulla standardizzazione della descrizione di collezioni documentarie, ma certamente la tipologia di documenti che ogni unità archivistica potrebbe potenzialmente conservare merita particolare attenzione. E qui entra in gioco il problema della complessità della descrizione, perché ogni documento richiede un modello di rappresentazione ad hoc11. E appiattire la descrizione su un modello condiviso significa perdere la capacità espressiva di tale materiale. Molto è stato fatto dagli enti deputati al rilascio degli standard per la descrizione di materiali speciali - si pensi ai lavori fatti dall'ICCU su musica e materiale grafico (manifesti, stampe e disegni)12 o dall'ICCD su fotografie, opere d'arte, oggetti archeologici13, ma anche i progetti su pergamene o sigilli elaborati in occasione della creazione di SIAS14 - ma molto ci sarebbe ancora da fare. L'obiettivo finale deve essere quello di agevolare il dialogo fra tipologie documentarie difformi, ciascuna delle quali in grado di trasmettere un sapere autonomo, ma al contempo capace di intrattenere collegamenti con altre risorse. Ed è dalle relazioni che nasce la conoscenza.
Il secondo tema è infatti quello della costruzione delle relazioni. Gli archivi di persona sono un patrimonio immenso di sapere. Non solo per le relazioni che le persone intrattengono con la documentazione prodotta, ovvero con il complesso documentario, ma anche per le connessioni che le persone, intese come record d'autorità, sono in grado di istituire con altre persone. E senza dimenticare il fondamentale rapporto delle persone con tutta la documentazione, o anche le risorse informative, che ad un qualche livello sono ascrivibili alla loro responsabilità. ISAAR-CPF15 traduce in metodologia il processo di creazione di record di autorità, riservando alle sezioni dedicate alle relazioni fra persone, al collegamento fra persone e documentazione archivistica, ma anche le connessioni fra persone e altre risorse, un ruolo importante. E il sistema di controllo di autorità, o anche il punto di accesso controllato alle descrizioni, è un vero importante elemento di contatto in ottica GLAM16. Da questo punto di vista la prospettiva della descrizione delle persone, così come elaborata dallo standard ISAAR-CPF, è il cardine attorno al quale far ruotare il sistema delle 'convergenze parallele' nel sistema beni culturali17.
Se non fosse che il collegamento con le altre risorse, quello che arricchirebbe la descrizione del record autorità, è spesso di difficile gestione in un contesto strettamente archivistico, e viene per questo spesso trattato in modo non soddisfacente. La limitazione nella costruzione di collegamenti comporta una limitazione della capacità del fruitore finale di arrivare alla conoscenza, di arricchire la propria esperienza di consultazione attraverso l'esplorazione di informazione semanticamente correlata. Come vedremo oltre, se da un lato l'assenza di collegamenti, o il numero limitato di risorse linkate, è determinata da questioni strettamente tecniche - come per esempio la chiusura di certi sistemi di accesso alle risorse, che ne impediscono il riuso in contesti diversi da quello d'origine - dall'altro la dichiarazione di spesso generici related items, limita le funzionalità del processo di interlinking a livello semantico.
Un esempio aiuterà. Il sistema di gestione delle relazioni in ISAAR-CPF copre, come si diceva, tre livelli: persona-persona, persona-complesso documentario, persona-altre risorse correlate. La relazione persona-persona è quella più facilmente risolvibile attraverso la definizione di collegamenti fra autorità identificate univocamente; il collegamento persona-complesso documentario è altrettanto semplicemente determinabile attraverso la costruzione di un sistema di interlinking fra authority record persona e identificativo del complesso documentario prodotto; la relazione fra persona-altre risorse ascrivibili a quella persona, fuori da un contesto strettamente archivistico (giusto per semplificare potranno essere classificabili come altre risorse un libro, una fotografia, un quadro o una statua in qualche modo correlate alla persona), non saranno così semplicemente realizzabili in assenza di un sistema di identificazione univoca delle risorse ascrivibili alla responsabilità di quella persona. Se allora il record bibliografico è in un sistema chiuso o la descrizione del quadro non consente la qualificazione univoca di quella risorsa, la relazione persona-risorse ascrivibili non può essere risolta. Se poi si passa al problema della tipizzazione delle relazioni la questione si complica su tutti e tre i livelli. Quale rapporto 'associativo' esiste fra una persona e un'altra? Perché sono 'associate'? Perché una persona è collegata ad una fotografia? Perché ne è l'esecutore materiale, vi è raffigurato, o, per esempio, è lo stampatore?
Quindi, se il modello che ISAAR-CPF detta, in termini di relazioni tripartite, è un riferimento che deve guidare il sistema dei GLAM, la concettualizzazione di tale modello deve passare attraverso una serie di processi che sono oggetto di riflessione nelle prossime sezioni.
Un primo passo verso il processo di integrazione è rappresentato dalla scelta del formato di rappresentazione informatica degli elementi della descrizione, tanto a livello di complesso documentario, quanto a livello di soggetti produttori. L'elaborazione dei due modelli EAD18 e EAC-CPF19, che traducono gli standard ISAD e ISAAR in schemi formali, ha dato una prima soluzione al problema dell'interoperabilità. L'adozione di XML, come meta linguaggio dichiarativo semi-strutturato per la trasformazione di stringhe di caratteri non interpretabili in sequenze dotate di un primo livello di formalizzazione sintattica, ha garantito il dialogo e l'interscambio fra descrizioni archivistiche a livello, appunto, sintattico.
La rappresentazione digitale dell'informazione di natura archivistica ha richiesto allora l'adozione del linguaggio XML e di due schemi che agevolino il dialogo fra istituzioni di conservazione diverse20.
Con EAD la rappresentazione gerarchica ad albero dei complessi documentari garantisce il rispetto dello standard metodologico. Il livello dell'item, in qualità di elemento finale della catena della descrizione, è quasi sempre limitato, nei progetti che utilizzano EAD, agli elementi obbligatori secondo le direttive ISAD: identificativo univoco o segnatura, titolo, estremi cronologici, consistenza (numero di pezzi e unità di condizionamento), soggetto produttore (in genere indicato a livello gerarchicamente superiore, che sia la serie o il fondo), livello di descrizione, e, aggiungerei, eventuali strumenti di ricerca disponibili (se già non si sta descrivendo a livello di inventario).
Ora standard diversi possono contribuire ad una più analitica descrizione a livello di item. E gli item che qualificano le raccolte di persona sono tipicamente, come si diceva, estremamente eterogenei. Questo significa riconoscere il problema del rapporto fra standard elaborati nel contesto dei GLAM, cercando soluzioni per il dialogo fra modelli di descrizione originariamente deputati a risolvere un bisogno strettamente legato alla tipologia documentaria. Ecco allora che un foglio volante, una fotografia, un quaderno di appunti, un manufatto o una mappa, avranno bisogno di elementi di metadatazione differenti, nel rispetto delle specificità documentarie, ma al contempo di strumenti di mappatura per garantire l'interscambio.
Anche per quanto riguarda la descrizione di singole tipologie documentarie, la situazione non è così canonizzata. Un'attenzione speciale hanno sempre ricoperto i carteggi, come esempio di serie illustri nei fondi di persona. In assenza però di uno standard ufficiale di riferimento per la definizione degli elementi dell'oggetto lettera21, i progetti orientati alla descrizione dei carteggi adottano modelli descrittivi diversi (si vedano le fig. 1, 2, 3 e 4 per notare la variabilità del sistema di descrizione nei quattro progetti presentati). Pur nella condivisione di un sistema di interscambio (che almeno a livello base contempla fra gli elementi: una segnatura, un mittente, un destinatario, una data topica e una data cronica) le variazioni ci sono (solo per fare qualche esempio, presenza di notizie relative a misure della carta, scrittura, tipologia di supporto materiale, o ancora presenza di regesto, incipit ed explicit, elementi di soggettazione). E i carteggi sono esattamente quella tipologia documentaria che tradizionalmente lega la descrizione archivistica ai principi della descrizione uniforme del manoscritto, e quindi alla menzione degli aspetti codicologici, oltre a richiamare l'attenzione, in particolare, dei filologi, con il patrimonio di sapere che questi ultimi sono in grado di apportare alla descrizione.
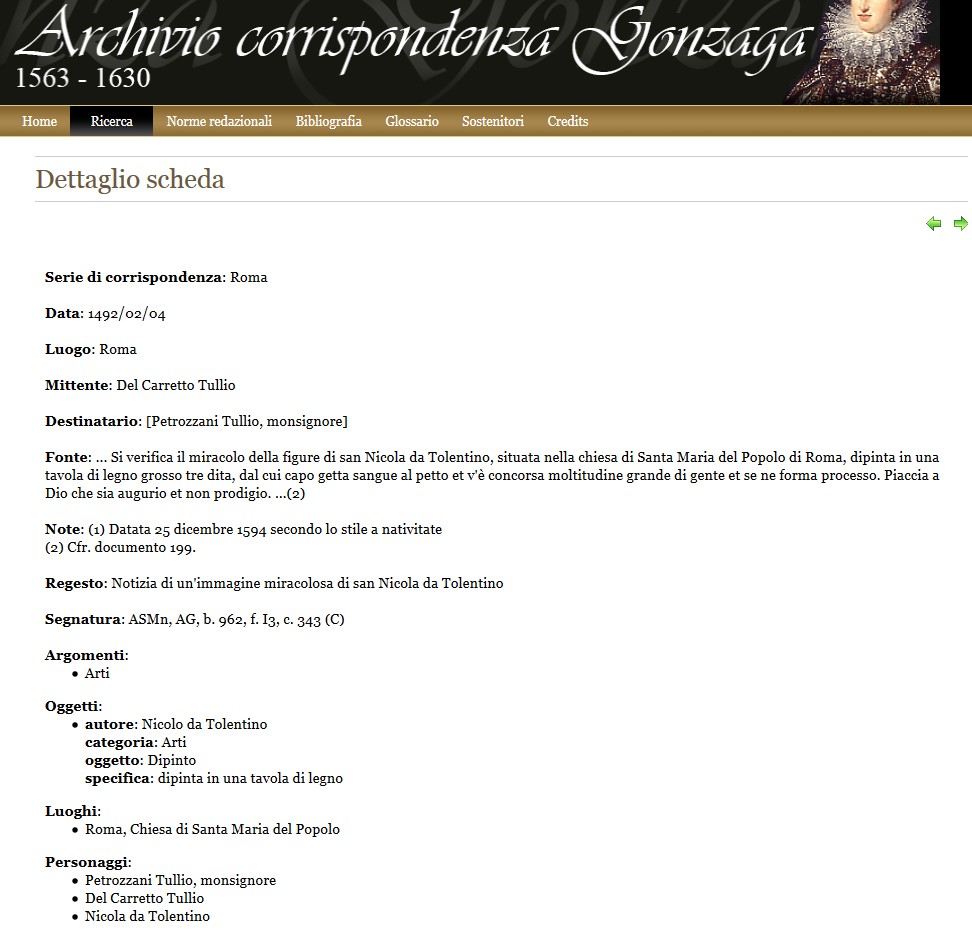

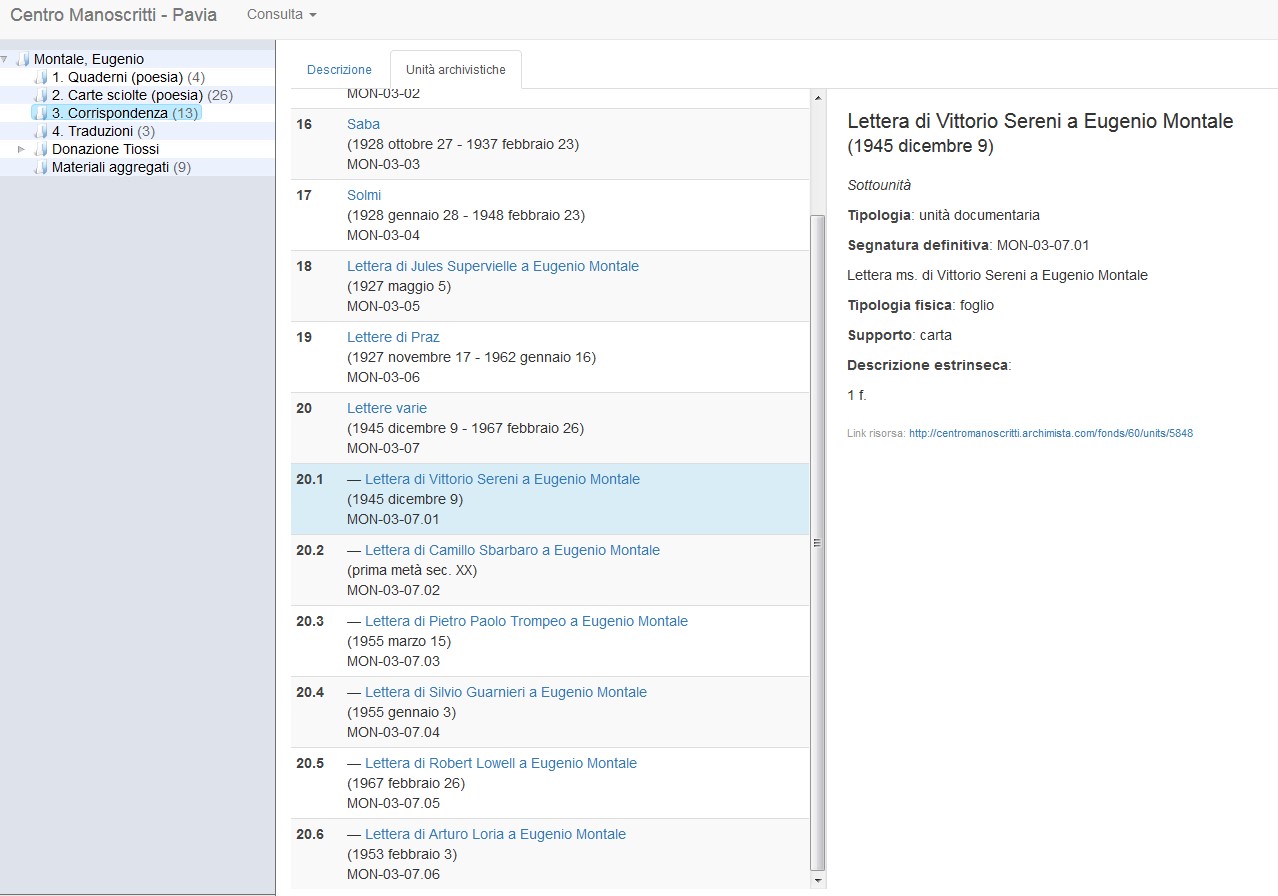
La stessa variabilità si registra a livello di soggetto produttore. Il grado di analiticità della descrizione, oltre ai quattro elementi obbligatori contemplati da ISAAR-CPF (tipologia di soggetto produttore, forma autorizzata del nome, date e codice identificativo del record di autorità), è un aspetto che può compromettere l'interscambio a livello semantico. Tanto più poi il soggetto produttore è ricco di elementi utili a qualificarlo da diversi punti di vista, tanto più l'esperienza informativa ne trarrà beneficio (si veda per esempio il livello di profondità attraverso cui sono descritti i soggetti produttori nel progetto SNAC, cfr. fig. 5, pur nell'impiego di generiche relazioni associative fra persone).
A questo si somma la non neutralità del processo descrittivo rispetto alle aree di classificazione delle descrizioni secondo le direttive dello standard ISAAR-CPF. La stessa separazione delle relazioni fra persone (Area delle relazioni, area 5.3) dalle relazioni fra persone e documentazione (Area del collegamento degli enti, persone e famiglie con la documentazione archivistica e con altre risorse, area 6) può essere motivo di ambiguità espressiva26.
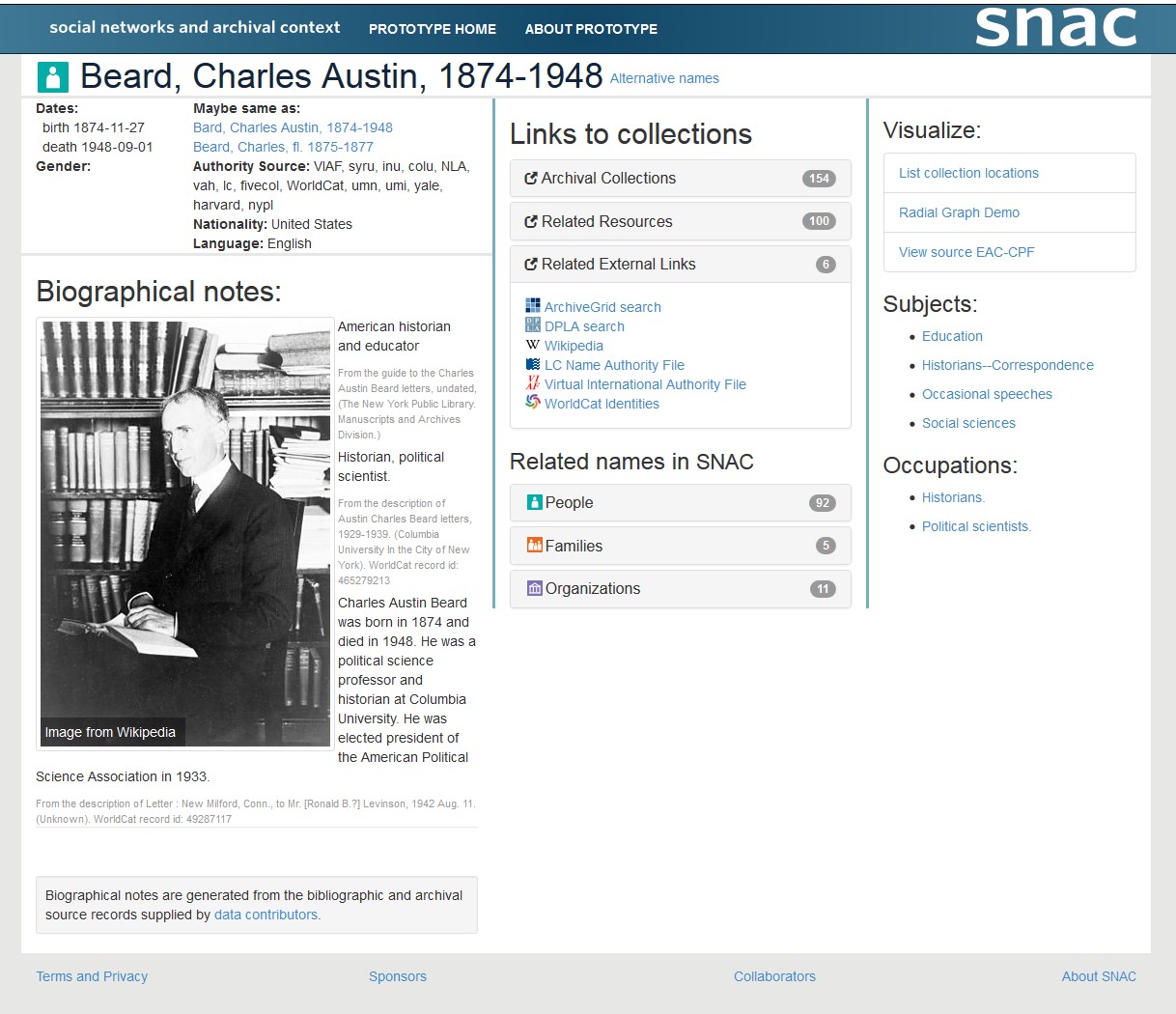
Il ruolo di ISDF28 non è irrilevante in questo contesto. Il concetto di ruolo e di funzione contribuisce a dare valore alla descrizione ed è un elemento determinante per arricchire la posizione dei soggetti produttori nel ciclo vitale del documento, in termini di specificazione della provenance. Ma, anche in questo caso, e come accade in tutti gli standard metodologici, l'eccesso di ambiguità nella tipizzazione delle funzioni (per esempio la semplificazione della 'category of relationship' - ovvero la relazione fra entità e funzione - in gerarchica, associativa e temporale) e l'assenza di un vocabolario controllato per ruoli e funzioni (mancanza di una tassonomia della 'nature of relationship'), rischia di limitare la profondità semantica da un lato e l'interoperabilità dall'altro. Nel dettaglio poi lo standard ISDF non fornisce una definizione specifica delle funzioni e dei ruoli, ma attribuisce funzioni (attività e occupazioni) agli enti e ruoli alle persone, senza stabilire come distinguere la descrizione di ruolo o di una funzione dai tipi di ruoli che una persona può avere, o ancora senza fornire strumenti per normalizzare i tipi di relazione che un ruolo può avere con la documentazione archivistica o con altre risorse ascrivibili29.
Se dunque la sintassi garantisce l'interoperabilità a livello di formato, e gli schemi un primo livello di interscambio in termini di vocabolario controllato, nulla ancora è risolto a livello di interoperabilità semantica. Le descrizioni di complessi documentari rimangono allora spesso silos di dati e gli authority records delle entità autoreferenziali.
Il problema sostanziale diventa allora come trasformare questi dati in reale conoscenza fruibile non solo dalle macchine, ai fini del ragionamento automatico, ma soprattutto dall'utente finale, quale destinatario del sapere. Se la conoscenza deriva dalle relazioni, allora dal metalinguaggio è necessario passare ad un framework di descrizione di risorse informative, e dagli schemi ai modelli concettuali.
Su due aspetti andrà allora esercitato l'arricchimento semantico: la gestione di documenti eterogenei per tipologie, e quindi per elementi della descrizione, e la valorizzazione degli aspetti di relazione.
Le direttive che il web semantico ha iniziato a impartire riguardano un passaggio non indolore nelle modalità di rappresentazione digitale. Prime fra tutte l'esigenza della transizione da una prospettiva documento-centrica ad una dato-centrica. Questo ha significato una ridefinizione del web come una rete di collegamenti non più fra documenti non qualificati e attraverso relazioni non esplicite, ma fra dati, ovvero unità atomiche riferibili a 'cose', identificate in modo esplicito, e correlate attraverso link semanticamente determinati, cioè capaci di auto-esplicitare la propria funzione (cfr. fig. 6).

Da questo punto di vista, la descrizione archivistica non ha dovuto modificare la sua tradizionale metodologia. L'identificazione univoca di frammenti atomici come entità dotate di proprietà di diversa tipologia e ordine è una specificità della descrizione archivistica, ed è al contempo la prima direttiva dei LOD. La descrizione archivistica ha tradizionalmente basato il proprio modello sulla qualificazione di porzioni logiche, che significa attribuzione di stringhe ad una categoria descrittiva (per esempio un nome, una data, un luogo) e la normalizzazione delle forme (per esempio Albini Giuseppe; 1863-1933; Bologna).
Due sono i problemi che, dal punto di vista della descrizione archivistica, rimangono insoluti: da un lato l'eccesso di narratività per alcune aree della descrizione (in particolare l'area delle informazioni contestuali) e dall'altro l'assenza di specificazione delle relazioni, in particolare fra persone, che vadano oltre la classificazione canonica (relazione associativa, cronologica, gerarchica e familiare). L'eccesso di sezioni narrative in un sistema altamente strutturato, come quello della descrizione archivistica, rende il testo contenuto in quelle sezioni non ulteriormente manipolabile sul piano computazionale. L'assenza di specificità della tipizzazione delle relazioni fra persone rende complicata la creazione di cluster di relazioni più analitiche rispetto a quelle canoniche (cfr. fig. 7 dove, come da specifiche dello standard, la descrizione della persona è una sezione narrativa non ulteriormente strutturata, e le relazioni fra persone sono genericamente 'relazioni associative').
Un primo passo sarebbe quindi da un lato attribuire descrittori anche alle parti narrative che rimandino a concetti qualificabili come dati atomici e dall'altro lavorare sulla costruzione di tassonomie che meglio specifichino le tipologie di relazioni rispetto alle macro-categorie.

Ma siamo ancora a livello di dato. La stringa enucleata, identificata univocamente e attribuita ad una categoria è ancora un dato. Essa inizia a diventare conoscenza quando le relazioni fra i dati vengono esplicitate in modo non generico e non ambiguo. Parliamo di conoscenza infatti come l'ultimo livello della piramide che dal dato (il fatto) ci consente di arrivare all'informazione (il dato arricchito) e da qui alla conoscenza (un'informazione organizzata). Esemplificando potremmo dire che se una stringa è il dato, la sua etichetta descrittiva fa diventare il dato informazione, ma è solo con le relazioni fra informazioni che è possibile dedurre la conoscenza.
La rete delle relazioni è il senso del passaggio alla conoscenza, intesa come strategia organizzativa. Le relazioni non sono infatti altro se non un tentativo di organizzare il sapere: indici, tesauri, tassonomie rappresentano il bisogno classificatorio come strumento per trasformare il dato in una conoscenza che deriva dalla posizione del dato in una struttura. Se la struttura è gerarchica, come nel caso della tassonomia, la conoscenza deriva dal rapporto del concetto con l'iponimo e l'iperonimo. Se la struttura è il grafo, come nel caso del tesauro, si aggiungono i rapporti sinonimici o associativi, che arricchiscono la gerarchia, innestando appunto la rete31.
Questa breve digressione è necessaria perché ci permette di comprendere come l'arricchimento semantico dei dati sia la traduzione dell'esigenza di organizzare il sapere attraverso strutture classificatorie nella forma del grafo. Non a caso il recente esperimento di Google con il knowledge graph32 sta definendo la tendenza del nuovo web di dati.
Se prendiamo un esempio di query di persona in Google (cfr. fig. 8), noteremo che l'ambiente ci restituisce, assieme al canonico elenco di risultati, una risposta altamente strutturata: qualificazione del nome di persona, collezione di elementi iconografici, ruolo (occupazione), dati anagrafici strutturati, collegamento con oggetti legati a quella persona, collegamento con altre persone correlate. Un approccio che richiama il metodo archivistico nella descrizione dei soggetti produttori.

Certo è che la risposta di Google con il knowledge graph, se in parte riproduce un modello interessante, ancora restituisce risultati dubbi. Non sempre i collegamenti sono sensati per l'utente finale e mai è esplicito il motivo della relazione (riprendendo l'esempio di fig. 8 sarà lecito chiedersi perché Tim Berners Lee sia in qualche modo in relazione associativa con Robert Cailliau o Vint Cerf o ancora Robert E. Kahn o con le altre persone suggerite nella sezione 'people also search for'). Ma di certo il grafo è il tipo di dato astratto - o meglio, con il concetto di rete, la struttura dati - più adeguato alla rappresentazione del sapere.
E certo il grafo è il modello che sta a fondamento dei LOD. Se dovessimo dunque dare una definizione di linked open data dovremmo riflettere su alcuni principi che governano la proposta di Tim Berners Lee fin dalle sue origini: i dati – nel loro rappresentare delle cose - devono essere univocamente identificati attraverso URI; devono essere utilizzati i linguaggi del web (HTML, XML, RDF); i dati devono essere accessibili via HTTP e interrogabili attraverso SPARQL; devono essere adottati link tipizzati. Ovvero i dati identificati in modo univoco devono essere fra di loro collegati semanticamente per creare un network accessibile33.
Ora come trasportare questi principi nel contesto di un arricchimento del patrimonio culturale che, prendendo a modello gli archivi di persona nelle loro specificità sopra descritte, risolva il grafo del cultural heritage?
Il patrimonio che la descrizione archivistica porta alla riflessione, nello specifico del lavoro sugli archivi di persona, è quello del lavoro sulla qualificazione del soggetto produttore assieme a quello dell'analisi delle relazioni fra persone e documentazione prodotta/correlata. Ma richiama contestualmente il problema della molteplicità degli oggetti documentari che in qualche modo sono collegati al soggetto produttore stesso: non solo la documentazione archivistica ma tutto ciò che, in ottica GLAM, può essere ascritto a quel soggetto, tanto a livello bibliografico che museale. Il principio del 'contesto', inteso archivisticamente come tutto, cioè che dà consistenza al documento archivistico a partire dalla sua creazione, è la chiave di lettura da adottare34.
Ci sono alcuni elementi descrittivi degli oggetti del patrimonio culturale che nel contesto LOD GLAMs sono ricorrenti (cfr. fig. 9), e che andrebbero sempre valutati considerando i livelli di rappresentazione previsti dal modello FRBR35:
- persone, ovvero l'attribuzione di paternità e/o autorialità rispetto a ruolo e funzione ricoperto in uno specifico contesto;
- luoghi, ovvero la geolocalizzazione a tutti i livelli della metadazione, assieme al concetto di luogo virtuale;
- date, ovvero la consistenza cronologica degli elementi della descrizione;
- eventi, ovvero la consapevolezza della relazione fra persone, luoghi e date come elementi utili a determinare un fatto, ovvero anche un oggetto o un concetto.
Detto in altri termini, la prospettiva lato utente finale è l'accesso alle risorse informative sotto forma di entità correlate che, in un sistema di navigazione attraverso un'interfaccia a faccette, rispondano ai canonici quesiti who, when, where e what36 in prospettiva integrata evento-centrica, ovvero attraverso filtri (qualcuno che ha fatto qualcosa in un qualche luogo e in una certa data producendo un certo risultato).
Questa posizione consente di avviare una riflessione sugli elementi della descrizione condivisi e sulla spontanea rete di relazioni che ne derivano: se l'utente finale deve avere la possibilità di accedere attraverso questi filtri, il modello concettuale che sta dietro al dataset deve prevedere classi e proprietà in grado di soddisfare questo bisogno.

Senza dimenticare però un problema già menzionato: molte collezioni culturali sono ancora chiuse in sistemi inaccessibili, con la conseguenza che i datasets nel LOD cloud38 per il settore cultural heritage non sono ancora in numero sufficiente a dare una consistenza importante al sistema delle relazioni39.
Per arrivare ad un reale arricchimento semantico è necessario riflettere allora ad un livello di astrazione più alto, ovvero a livello di modello concettuale. La modellazione è un processo di interpretazione della realtà di un dominio attraverso opportune 'lenti semantiche'40, capace di fornire una visione del dominio stesso che può essere condivisa nel sistema GLAM.
L'ontologia, in qualità di concettualizzazione formale di un dominio, è lo strumento per trasformare il dato in conoscenza. Ed è con l'ontologia che si inizia a ragionare in termini di organizzazione del sapere. RDF41 consente di esprimere la descrizione della realtà osservata attraverso asserti, ovvero triple che, con il meccanismo di soggetto-predicato-oggetto, danno consistenza semantica al metadato. Ma è solo con l'ontologia e quindi L'ontologia, in qualità di concettualizzazione formale di un dominio, è lo strumento per trasformare il dato in conoscenza. Ed è con l'ontologia che si inizia a ragionare in termini di organizzazione del con le logiche descrittive che è possibile il ragionamento e quindi che la conoscenza può essere estratta. Ovvero solo la formalizzazione del sapere, cioè la traduzione di modelli concettuali attraverso linguaggi ontologici, come OWL42, consente ai dati di diventare conoscenza43. L'adozione di un modello concettuale è un primo passo verso una prospettiva di integrazione dei dati. Pensando al contesto specifico del cultural heritage, e alla molteplicità di funzioni che un'ontologia può svolgere, il ruolo del modello concettuale deve essere innanzitutto quello di uno strumento volto a consentire l'interscambio semantico.
Se il passaggio dagli standard metodologici agli standard formali è un primo step di processo, il passaggio dagli schemi alle ontologie è il vero scarto concettuale. Ma è solo attraverso i sistemi di dialogo a livello semantico che l'integrazione può diventare possibile. E tale livello semantico deve garantire la preservazione del massimo contenuto informativo del dato, in qualità di oggetto complesso, governato da tre parole chiave: eterogenità, interconnessione e profondità. Il caso di EDM44 ha mostrato come lo sforzo verso il rilascio di linee guida per aggregare risorse eterogenee possa aver agevolato un primo dialogo fra oggetti del patrimonio. Rimane l'appiattimento del risultato lato utente sul vocabolario del Dublin core che, oltre a limitare a quindici il numero di categorie descrittive, presenta un generico livello di risorse correlate (related to), senza ulteriormente specificare la natura del collegamento45.
Creare un modello ontologico per il GLAM è tipicamente attività che richiede un approccio plurimo46:
- Traduzione di standard di metadati esistenti in ontologie. Uno sforzo andrà fatto per rendere i vocabolari di metadati delle ontologie, quindi per trasformare set di descrittori (che siano vocabolari o schemi) in modelli concettuali e quindi in strumenti formali, ovvero computabili.
- Confronto, o allineamento, fra modelli ontologici già esistenti. Un aspetto determinante ai fini dell'interoperabilità è il matching, ovvero la verifica del parallelismo fra classi e predicati utilizzati in ontologie diverse. Lungi dall'essere un'operazione semplice, tale attività, quando formalizzata, rende più facile il dialogo fra modelli.
- Creazione di nuove classi e predicati da integrare in ontologie già esistenti. Un altro aspetto, questo, da valutare. E' possibile procedere con l'adozione di un'ontologia già esistente, integrandovi nuove classi e predicati necessari ad arricchire il modello o prendere classi e predicati, capaci di risolvere la concettualizzazione, da altre ontologie e integrandoli poi nel modello scelto (merging).
- Creazione di nuove ontologie. Quest'ultima operazione ha senso se e solo se nessuno dei modelli già disponibili soddisfa le esigenze di modellazione di un dominio, o meglio di uno speciale aspetto del dominio non valutato in altri modelli.
Il modello concettuale non deve sostituirsi alle specificità della descrizione delle risorse, ma porsi ad un più alto livello di astrazione, come strumento per consentire il dialogo fra sistemi di descrizione eterogeni. Per questo è necessaria l'adozione di tecniche di mapping, ovvero di traduzione, ma anche di confronto e allineamento fra sistemi di descrizione, per creare un modello condiviso cui diverse ontologie possono riferirsi. Il mapping è quello stadio in cui è possibile mantenere la specificità del proprio sistema di descrizione, ma allo stesso tempo allineare il proprio sistema ad una o più ontologie esistenti.
Sono numerose le ontologie elaborate nel dominio del cultural heritage47. Alcune sono create ad hoc, altre sono traduzioni di set di metadati: la già citata ontologia del SAN48, la EAC-CPF ontology49, OAD del progetto Reload50, CIDOC CRM51 e il correlato FRBRoo52. Ciascuna ontologia modellizza il dominio rispetto ad uno speciale punto di vista e ciascuna è in grado di risolvere un certo livello di concettualizzazione. Ma ci sono altre ontologie che tipicamente vengono riusate perché non lavorano su un dominio specifico ma risolvono un bisogno concettuale, come PRO53, per la gestione dei ruoli, PROV-O54, per la provenance o CiTO55, per i sistemi citazionali.
Il recente lavoro condotto da EGAD (Expert Group on Archival Description) che ha portato all'elaborazione di un primo modello di descrizione della realtà archivistica, ovvero RIC-CM (Records in context - conceptual model)56, ambisce esattamente a muoversi nella prospettiva della creazione di una nuova ontologia che acquisisca i modelli archivistici già in uso (ISAD-ISAAR-CPF, ISDF e ISDIAH57) integrandoli con elementi provenienti da altri standard, per raggiungere l'obiettivo di fornire un servizio all'intera comunità del cultural heritage.
Persona e oggetto sono i due livelli attorno a cui ruota la descrizione delle risorse informative: documenti e agenti sono allora il punto di partenza, come ISAD e ISAAR-CPF, ma anche ISBD58, FRAD59, RDA60 e REICAT61, ci insegnano.
Ecco allora che la descrizione per singola tipologia documentaria e l'interconnessione fra persone, e fra persone e risorse, deve risolversi innanzitutto a livello di modello concettuale. Se quindi gli standard metodologici, in particolare in campo archivistico, forniscono un modello teorico utile in ottica di integrazione nel GLAM, essi devono essere ripensati in termini di modello concettuale, per supplire a quelle mancanze che, naturalmente, lo standard metodologico detiene. Ovvero ogni singola ontologia, da diversi punti di vista, può fornire un supporto per trasformare la potenziale ambiguità e indeterminatezza degli standard metodologici in conoscenza elaborabile dalle macchine in modo automatico.
Il lavoro condotto sull'Archivio Zeri sarà allora utile per chiarire la funzione dei diversi modelli ontologici nel processo di concettualizzazione di dominio, ma anche nella fase successiva di creazione del dataset secondo i principi LOD.
L'Archivio fotografico di Federico Zeri dell'Università di Bologna mette a disposizione della comunità un'imponente e preziosa collezione di fotografie di opere d'arte d'Europa (290.000 esemplari), accompagnata e documentata da una ricca biblioteca di storia dell'arte (46.000 volumi), da una delle più imponenti raccolte di cataloghi d'asta (37.000 cataloghi), nonché dai preziosissimi appunti del suo creatore (15.000 documenti archivistici).
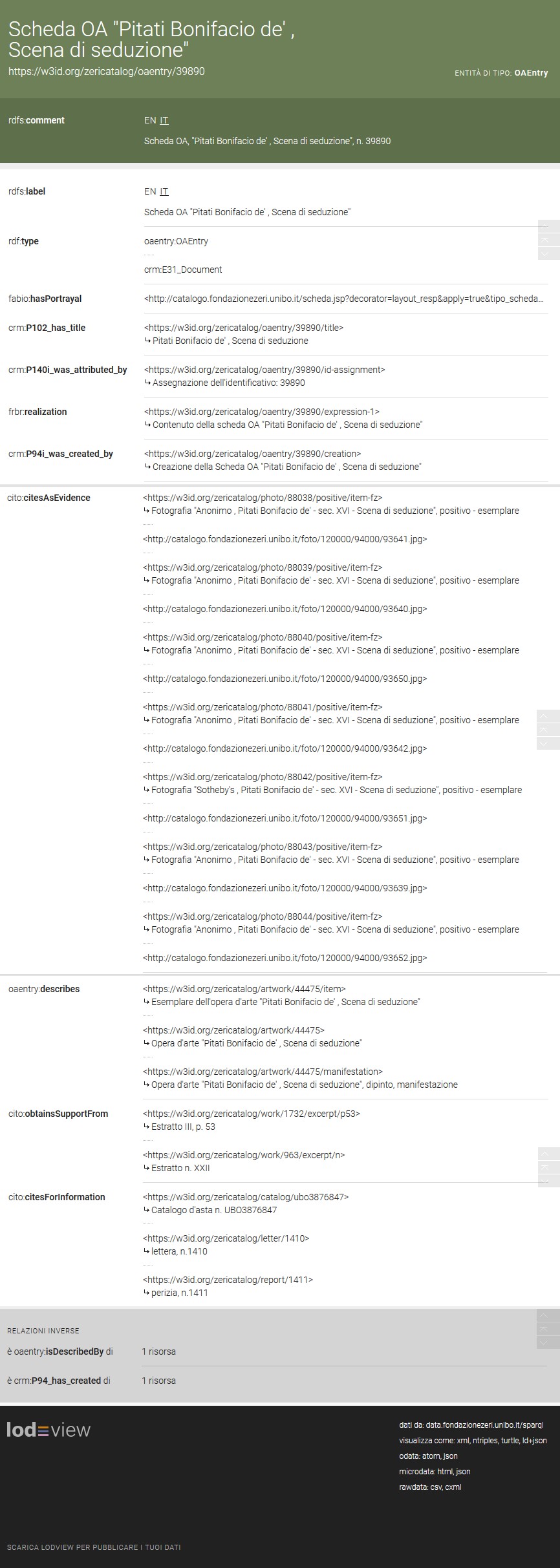
Per esemplificare concretamente le riflessioni qui elaborate, potrà allora essere utile presentare il lavoro svolto su questo archivio fotografico, che è anche il fondo personale di un'illustre personalità, cioè Federico Zeri62. Un archivio di personalità dunque che testimonia tanto della varietà di tipologie documentarie conservate (fotografie, biblioteca, cataloghi d'asta, lettere e perizie), quanto della pluralità di sistemi di relazioni che il fondo veicola. Nonostante la specificità del caso particolare, un archivio fotografico di opere d'arte prodotto da un importante critico63, questo esempio ben si presta ad evidenziare tutte le problematiche presentate, e che si risolvono nel tentativo di riprodurre in linked open data i dati di un patrimonio culturale eterogeneo di incredibile valore per lo studioso di storia dell'arte. Tale patrimonio è infatti rappresentato da: il catalogo e la descrizione archivistica di un fondo peculiare per ordinamento e obiettivi, il repertorio di opere d'arte raffigurate, la vasta biblioteca di storia dell'arte e la documentazione d'archivio, che spazia dai report tecnici sull'analisi e l'attribuzionismo fino ai cataloghi d'asta64. Ciascun documento mantiene, nella base di conoscenza, le specificità descrittive dello standard di riferimento e attraverso interconnessioni l'informazione è relazionata, o va a formare un grafo della conoscenza. Dunque ogni asserto nel dataset RDF relaziona l'entità, ovvero il soggetto, all'oggetto collegato attraverso un predicato funzionale; ciascuna proprietà, sulla base dell'ontologia di riferimento necessaria ad esprimere un preciso concetto, valorizza l'espressività della tripla (si veda un esempio di descrizione di un'entità in fig. 13).
Il progetto ha anche voluto tradurre in un nuovo modello di rappresentazione, vale a dire RDF, gli standard di catalogazione ministeriali Scheda F65, per la descrizione della fotografia, e Scheda OA66, per la descrizione di opere d'arte, nonché le altre normative dell'ICCD per la redazione di record bibliografici inerenti la documentazione allegata67, la descrizione archivistica e gli authority file degli artisti e fotografi68. La pratica di tradurre standard di metadatazione in ontologie è stato allora un passo importante. Le risultanti ontologie, OA entry ontology69 e F entry ontology70, e i mapping degli standard F/OA a RDF71, hanno richiesto l'analisi puntuale delle soluzioni di rappresentazione formale tanto in contesto catalografico che archivistico. Considerando le buone pratiche di riuso nel semantic web, e quindi il reimpiego di modelli considerati standard de facto, si è cercato di unirvi modelli necessari a valorizzare la massima capacità espressiva del fondo. Il modello concettuale finale (OA entry ontology + F entry ontology) è quindi il risultato dell'unione di: pratiche di creazione di nuove classi e proprietà, processi di traduzione da standard di metadati, sistemi di mapping e riuso. In particolare l'ontologia CIDOC CRM è stata usata tanto come riferimento per il mapping (parallelismo fra campi della Scheda F e della Scheda OA e classi/proprietà di CIDOC CRM), quanto come modello per la descrizione degli oggetti culturali. Le SPAR ontologies (FaBiO, CiTO e PRO)72, nate nel contesto del 'publishing domain', hanno risolto l'esigenza di: utilizzare FRBR, anche estendendolo (ontologia FaBiO), di gestire i ruoli nel tempo (PRO) e di rispettare i sistemi citazionali e la menzione delle fonti di riferimento (CiTO). Per finire, un'ontologia in particolare è stata considerata necessaria alla completa definizione dello scenario e alla valorizzazione del complesso documentario: HiCO ontology, un modello realizzato per descrivere la provenance delle asserzioni fatte dai catalogatori e dai critici, e che include la possibilità di descrivere metodi di ricerca, criteri e fonti utilizzate, estendendo le potenzialità del già citato modello PROV-O73.
Ontologie dunque necessarie alla creazione del dataset: con il progetto Zeri si è creata una base di conoscenza (dati e ontologie) capace di dialogare con il resto del web. Un passo in questa direzione è stato anche la costruzione della rete di relazioni con le esistenti autorità per persone, luoghi e oggetti e quindi con: VIAF74, AAT thesaurus e Getty ULAN75, DBpedia76 e Wikidata77, Geonames78. L'estensione delle relazioni ad altre persone correlate a Zeri e ad altre risorse in qualche modo relazionate è parte del progetto Pharos, un consorzio internazionale di archivi fotografici, dentro al quale siede la Fondazione Zeri79.
Si prenda allora un esempio, fra i più attestati nel fondo, che ben sintetizza la pluralità di tipologie di risorse e la molteplicità di collegamenti tipizzati fra risorse e fra persone: una lettera di Zeri, in cui il critico parla di un'opera d'arte. Tale opera è riprodotta in potenzialmente diversi esemplari fotografici, alcuni in Archivio Zeri, altri in differenti fondi fotografici. Sul retro di uno di questi esemplari Zeri attribuisce la paternità dell'opera, attribuzione utile ad arricchire il campo di descrizione autoriale della scheda catalografica, e nella biblioteca privata di Zeri tale attribuzione di paternità è rafforzata da un saggio critico. Partendo da questo esempio, potrà essere utile chiudere il presente contributo simulando una navigazione nel Fondo Zeri80. In particolare si considera di seguito un'opera la cui attribuzione è stata oggetto di discussione, e la documentazione, o anche le fonti, necessarie a corroborare una certa paternità sono state riportate nella scheda descrittiva (cfr. fig. 10-12) e quindi concettualizzate e tradotte in triple RDF nel dataset (cfr. fig. 13).
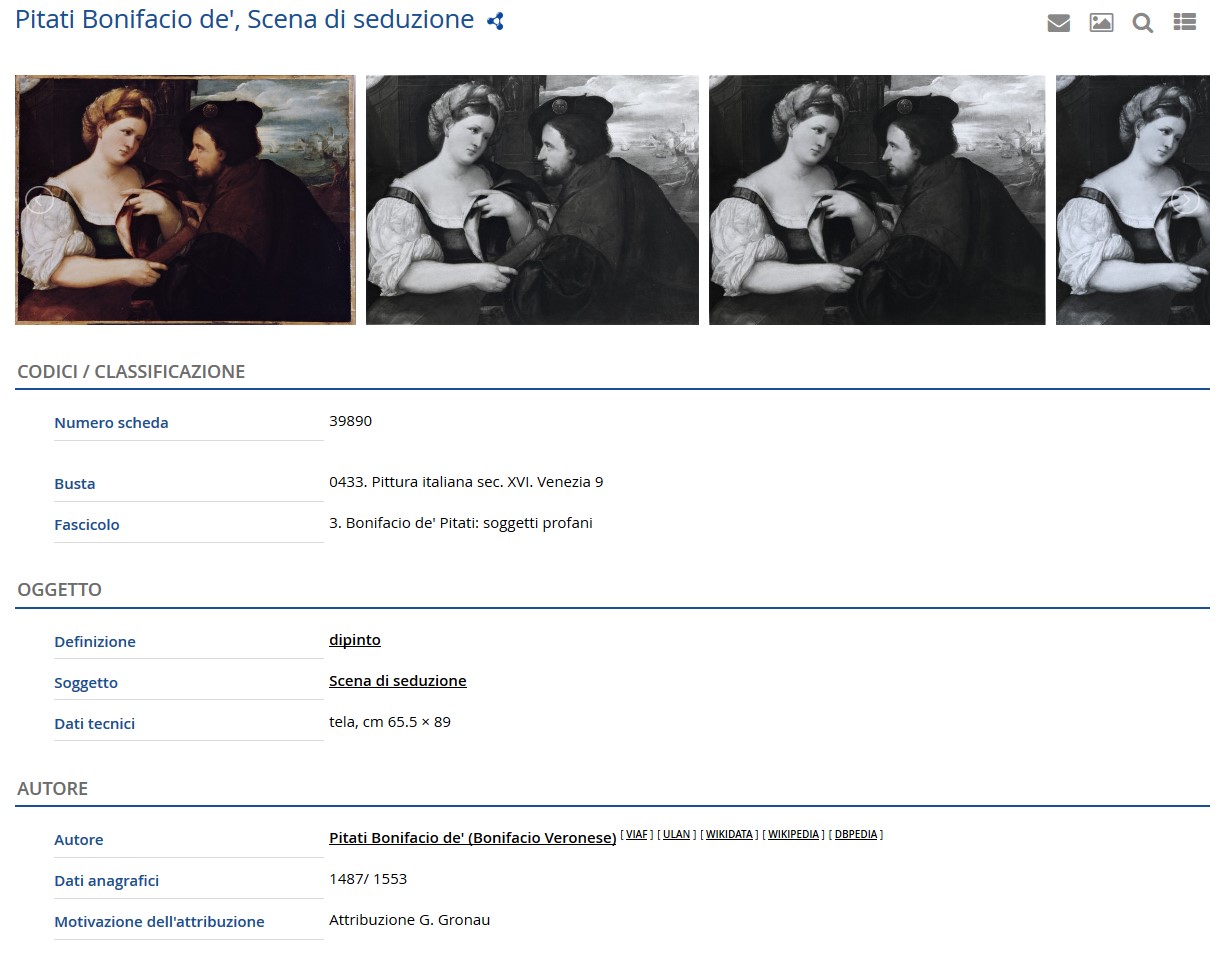

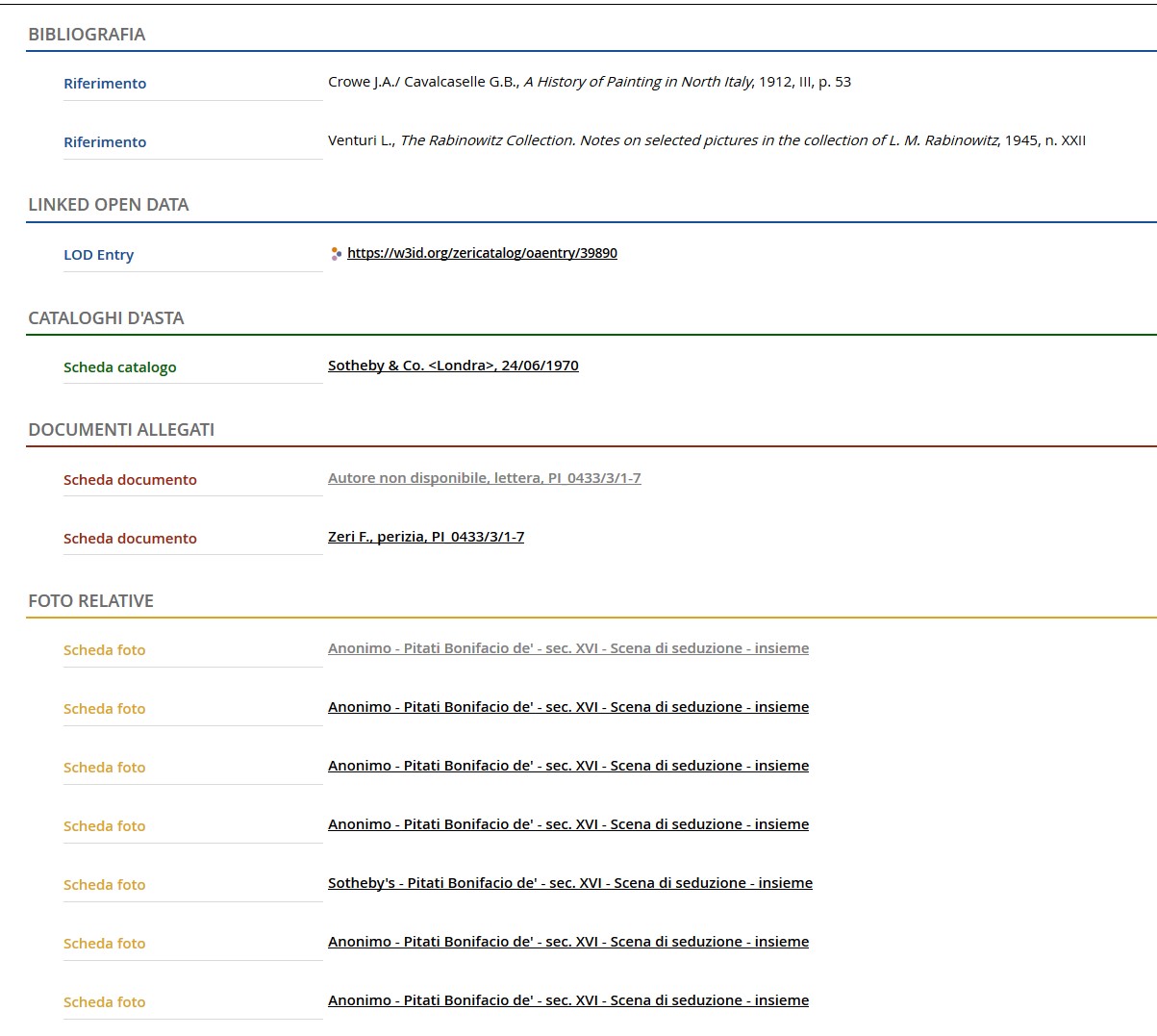
Da questa navigazione desumiamo allora tutti i dati descrittivi dell'opera: classificazione, identificazione e attribuzione di paternità, altre attribuzioni di paternità, datazione, dati sulla localizzazione, bibliografia, link ai cataloghi d'asta, collegamenti ai documenti d'archivio (una lettera e una perizia), serie delle fotografie che riproducono quell'opera.
E sarà allora utile, davvero in chiusura di contributo, presentare quella stessa scheda di catalogo attraverso una videata dell'entità descritta attraverso il nostro modello (cfr. fig. 13). Si potrà notare l'uso, in particolare, di alcune ontologie e quindi di specifiche proprietà:
- RDFS. Attraverso l'annotation property label si assegna un nome human-readable al soggetto, il cui oggetto è un literal, ovvero una stringa a testo libero; con comment si fornisce una descrizione del soggetto della risorsa.
- RDF. Con la proprietà type si specifica il soggetto come istanza di una classe: una OAEntry secondo l'omonima ontologia, un E31_Document secondo il modello CIDOC CRM.
- FRBR. Con il predicato realization specifichiamo che il work, ovvero l'opera, è realizzata attraverso una expression, ovvero un'espressione (che corrisponde al contenuto della scheda OA).
- CIDOC CRM. Si tratta dell'ontologia più usata nel dominio del cultural heritage, ed è risultata particolarmente importante nella concettualizzazione. Varie proprietà sono state riusate. In particolare in questo esempio si notano: P102_has_title per il titolo (in particolare il titolo di un'istanza di un Man-made thing); P140i_was_attributed_by per l'assegnazione dell'identificativo (39890); P94i_was_created_by per l'attribuzione di paternità alla compilazione della scheda OA da parte del catalogatore;
- Gruppo SPAR:
- FaBiO. La proprietà hasPortrayal collega un particolare work ai suoi items.
- CiTO. Vari predicati di CiTO sono stati riusati: citesAsEvidence per segnalare la serie delle fonti fattuali necessarie a corroborare le asserzioni fatte sull'entità in oggetto (nello specifico i diversi esemplari di fotografie, compresi i file immagine essi stessi, in termini di esemplari materiali); obtainsSupportFrom per riferirsi ad altre fonti che supportano una determinata caratteristica dell'entità (nel nostro caso due estratti di articoli, classificabili, secondo il modello FaBiO come excerpt - ovvero passi specifici in una fonte - in cui sono riportati commenti a supporto dell'attribuzione di paternità all'opera); citesForInformation per segnalare le fonti che danno conferma di un soggetto quando ne siano dibattute le caratteristiche (nel nostro esempio si tratta di un catalogo d'asta, una lettera e una perizia che di nuovo dichiarano l'attribuzione di paternità dell'opera).
- OAEntry. Con la proprietà describes si collega l'entità all'opera d'arte (fabio:ArtisticWork o anche crm:E28_Conceptual_Object), all'item (fabio:AnalogItem) e alla manifestazione (fabio:AnalogManifestation o anche crm:E22_Man-Made_Object).
Ecco dunque che il lavoro condotto sull'Archivio di Federico Zeri può essere un esempio di funzionamento di quel processo che costringe da un lato a far fronte alla naturale profondità e complessità della descrizione di oggetti culturali multiformi e dall'altro a porsi nell'ottica dell'interlinking come garanzia di espressività ma anche di esaustività del processo descrittivo. Garanzie entrambe di fare dei LOD uno strumento epistemologico.
[1] La letteratura sui LOD nel sistema beni culturali è aumentata esponenzialmente in questi ultimi anni. Esula dagli scopi del presente contributo fornire tutti i riferimenti, ma si veda in particolare il volume: Mauro Guerrini; Tiziana Possemato, Linked data per biblioteche, archivi e musei. Milano: Bibliografica, 2015.
[2] Il progetto DATI SAN LOD è consultabile alla pagina: http://san.beniculturali.it/web/san/dati-san-lod.
[3] Si veda in particolare, nel contesto LOD nel cultural heritage, l'iniziativa OpenGLAM http://openglam.org/ e il GLAM-Wiki https://outreach.wikimedia.org/wiki/GLAM. Il GLAM è, in Italia, equivalente al MAB (Musei, Archivi, Biblioteche), istituito nel 2011 da Associazione italiana biblioteche (AIB), Associazione nazionale archivistica italiana (ANAI) e International Council of Museums, Comitato nazionale italiano (ICOM Italia). Si veda http://www.mab-italia.org/.
[4] Il tema degli archivi di persona e di personalità è stato, ed è, oggetto di interesse da parte di comunità diverse: quella degli archivisti, ovviamente, ma anche quella dei filologi, in particolare nel settore degli archivi letterari. Non ci si soffermerà in questa sede sul problema di come comunità diverse intendano in modo altrettanto differente il concetto di archivio e le correlate pratiche di riordino e accesso. Sul tema si vedano in particolare: Il futuro della memoria: atti del Convegno internazionale di studi sugli archivi di famiglie e di persone, Capri, 9-13 settembre 1991. Roma: Ministero per i beni culturali e ambientali, Ufficio centrale per i beni archivistici, 1997 (gli atti sono consultabili all'indirizzo: http://www.archivi.beniculturali.it/dga/uploads/documents/Saggi/Saggi_45_2.pdf); Archivi di persona del Novecento: guida alla sopravvivenza di autori, documenti e addetti ai lavori, a cura di Francesca Ghersetti e Loretta Paro. Treviso: Fondazione Benetton studi e ricerche; Fondazione Giuseppe Mazzotti per la civiltà veneta; Crocetta del Montello: Antiga, 2012; Uomini e donne del Novecento: fra cronaca e memoria: atti degli incontri sugli archivi di persona, Università di Roma La Sapienza, 2009-2013, a cura di Azzurra Aiello, Francesca Nemore e Maria Procino, Mantova: Universitas studiorum, 2015; L'autore e il suo archivio: atti del convegno, Losanna, 28-29 novembre 2013, a cura di Simone Albonico, Niccolò Scaffai. Milano: Officina libraria, 2015. Fra i progetti archivistici in senso proprio si veda in particolare il lavoro sugli archivi di personalità elaborato dal Sistema informativo unificato per le soprintendenze archivistiche (SIUSA), nel Censimento dei fondi toscani fra '800 e '900, http://siusa.archivi.beniculturali.it/cgi-bin/pagina.pl?RicProgetto=personalita. In ambito filologico-letterario si vedano in particolare i progetti dedicati agli archivi dei letterati: Carte d'autore, http://www.cartedautore.it/, e l'attività del Centro manoscritti dell'Università di Pavia, http://centromanoscritti.archimista.com/. Fra le iniziative più recenti, si segnala la recensione alla giornata di studi, organizzata da AIB, “Fondi e collezioni di persona e personalità negli archivi, nelle biblioteche, nei musei: una risorsa, un'opportunità” (Bologna, 26 ottobre 2016), che si legge in: Federica Rossi, Fondi e collezioni di persona e personalità negli archivi, nelle biblioteche e nei musei: una risorsa, un'opportunità, «Bibliothecae.it», 7 (2017), n. 1.
[5] Senza dimenticare che il concetto di documento in senso archivistico allude a qualunque opera dell'intelletto, quindi anche libri, artefatti e oggetti in senso lato (Paul Otlet, Traité de documentation: le livre sur le livre: théorie et pratique. Bruxelles: Mundaneum, 1934). Interessante, sul tema degli archivi di persona ibridi, il recente volume: Gli archivi di persona nell'era digitale: il caso dell'archivio di Massimo Vannucci, a cura di Stefano Allegrezza, Luca Gorgolini. Bologna: Il Mulino, 2017.
[6] 5 stars open data, http://5stardata.info/en/.
[7] Sito ufficiale della Fondazione Zeri: <http://www.fondazionezeri.unibo.it>. Il progetto, di cui si forniranno tutti i dettagli nell'ultima parte del lavoro, è consultabile all'indirizzo: http://data.fondazionezeri.unibo.it/.
[8] «Ciò che è importante per la ricerca non consiste solo nella corretta descrizione e identificazione del documento, ma si estende alla sua contestualizzazione, cioè ai vincoli che lo legano a tutti gli altri documenti della raccolta». Fabio Venuda, Le raccolte di documenti personali: uno studio per la ricerca e la valorizzazione, «AIB studi», 57 (2017), n. 1, p. 63-78.
[9] ISAD (G), General international standard archival description: Second edition, 1999, http://www.icacds.org.uk/eng/ISAD(G).pdf.
[10] ICA/CDS, Guidelines for the preparation and presentation of finding aids, 2001. Traduzione a cura di Francesca Ricci, «Rassegna degli archivi di Stato», LXIII (2003), n. 1, p. 335-349, http://www.archivi.beniculturali.it/dga/uploads/documents/Rassegna/RAS_2003_1.pdf.
[11] Particolarmente interessante il poster di Jenn Riley, Seeing standards: a visualization of the metadata universe, copy 2009-2010, che classifica 105 standard in uso nel settore cultural heritage organizzandoli per: domain, community, function e purpose, http://jennriley.com/metadatamap/.
[12] Istituto centrale per il catalogo unico, Norme per la catalogazione in SBN, http://www.iccu.sbn.it/opencms/opencms/it/main/standard/Norme_catalogazione_SBN/.
[13] Istituto centrale per il catalogo e la documentazione, Standard catalografici, http://www.iccd.beniculturali.it/index.php?it/473/standard-catalografici.
[14] Su pergamene e sigilli si veda il lavoro condotto dal Sistema informativo per gli archivi di stato (SIAS), http://www.archivi-sias.it/, che, fra il 2006 e il 2007, ha avviato un progetto di valorizzazione dei fondi diplomatici (secoli VIII-XVII), elaborando una scheda pergamene (Linee guida alla descrizione e alla gestione del patrimonio documentario. Volume II.2, La scheda pergamene, a cura di Pierluigi Feliciati, ICAR, 2006, http://eprints.rclis.org/8661/1/SIAS_4_perga.pdf) e una scheda sigilli (Linee guida alla descrizione e alla gestione del patrimonio documentario: Volume II.3, La scheda sigilli, a cura di Stefania Ricci, DGA, 2007, http://www.icar.beniculturali.it/biblio/pdf/lgsias/sias_4_sigilli.pdf).
[15] ISAAR (CPF), International standard archival authority record for corporate bodies, persons and families; second edition, 2003, http://www.icacds.org.uk/eng/isaar2ndedn-e_3_1.pdf.
[16] Si veda in particolare il volume: Authority control: definizione ed esperienze internazionali: atti del convegno internazionale, Firenze, 10-12 febbraio 2003. A cura di Mauro Guerrini e Barbara B. Tillett. Firenze: University Press, 2003.
[17] Stefano Vitali, Le convergenze parallele: archivi e biblioteche negli istituti culturali, «Rassegna degli archivi di stato», LIX (1999), p. 36-59.
[18] EAD, Encoded archival description, https://www.loc.gov/ead/. La versione corrente è EAD3 1.0 del 2015.
[19] EAC-CPF, Encoded archival context - corporate bodies, persons, families, http://eac.staatsbibliothek-berlin.de/. Dal 2016 i «Technical subcommittees on EAD and EAC-CPF were merged to the common technical subcommittee on encoded archival standards (TS-EAS)», https://www2.archivists.org/governance/handbook/section7/groups/Standards/TS-EAS.
[20] Peraltro quasi tutti gli applicativi software destinati alla descrizione di complessi documentari e di correlati soggetti produttori prevedono l'esportazione dei dati in formato XML/EAD o XML/EAC-CPF. Si veda in particolare il numero monografico: Software open-source per gli archivi, «Archivi & computer», 1 (2012).
[21] Senza dimenticare però i pur numerosi progetti locali, come quelli presentati nelle fig. 1, 2, 3 e 4. Se si ragiona in termini XML andrà menzionata la DTD Digital archive of letters in Flanders (DALF) del Centre for Scholarly Editing and Document Studies di Gent, http://ctb.kantl.be/project/dalf/dalfdoc/DTDfiles.html per la marcatura della corrispondenza (progetto del 2005 ora superseded). Il vocabolario è in stretta connessione con il progetto Text encoding initiative (TEI). Si veda: TEI Consortium, Guidelines for electronic text encoding and interchange, 2007, http://www.tei-c.org/Guidelines/P5/.
[22] http://datini.archiviodistato.prato.it/la-ricerca/scheda/ASPO00000207/datini-francesco-marco-e-luca-del-sera-e-comp-datini-francesco-marco-e-comp.
[23] http://banchedatigonzaga.centropalazzote.it/collezionismo/index.php?page=Visualizza&carteggio=10535.
[25] http://centromanoscritti.archimista.com/fonds/60/units/5848.
[26] Diverso il caso delle Norme italiane per l'elaborazione dei record di autorità archivistici di enti, persone, famiglie (NIERA), 2014, dove l'area delle relazioni è unica ed è organizzata su tre macro-livelli (a loro volta strutturati): collegamento alla documentazione; relazione con altre entità; collegamento ad altre risorse. Le specifiche si leggono: https://www.bucap.it/wp-content/uploads/2014/12/niera-epf-seconda-edizione-luglio-2014.pdf.
[27] http://socialarchive.iath.virginia.edu/ark:/99166/w60867n8.
[28] ISDF, International standard for describing functions, 2011, http://www.ica.org/en/isdf-international-standard-describing-functions.
[29] Si veda su questo aspetto: Marilena Daquino [et al.], Political roles ontology (PRoles): enhancing archival authority records through semantic web technologies, «Procedia computer science», 38 (2014), p. 60-67 (in particolare p. 66).
[30] http://archivi.ibc.regione.emilia-romagna.it/eac-cpf/IT-ER-IBC-SP00001-0000264.
[31] Non sarà un caso che l'organizzazione gerarchica prescritta come modello dalle direttive degli standard di descrizione archivistica sia oggetto di dibattito anche in seno alla stessa comunità archivistica. Si veda in particolare: Giovanni Michetti, Ma è poi tanto pacifico che l'albero rispecchi l'archivio?, in «Archivi & computer», 1 (2009), p. 85-95.
[32] Amit Singha, Introducing the knowledge graph: things, not strings, «Official blog (of Google)», 2012, http://goo.gl/zivFV.
[33] Tom Heath; Christian Bizer, Linked data: evolving the web into a global data space, «Synthesis lectures on the semantic web: theory and technology», 1 (2011), n. 1, p. 1-136.
[34] Daniel V. Pitti, Descrizione del soggetto produttore: contesto archivistico codificato. In: Authority control: definizione ed esperienze internazionali cit., p. 153-178
[35] Si intende l'analisi di un oggetto valutando i diversi livelli attraverso cui quell'oggetto si può descrivere: Work, expression, manifestation e item. IFLA, Functional requirements for bibliographic records. Munich: K.G. Saur Verlag, 1998, https://www.ifla.org/publications/functional-requirements-for-bibliographic-records.
[36] Un esempio, fra i vari, del modello era quello seguito dal portale Cultura Italia con il Pico thesaurus, «un vocabolario controllato, progettato per la soggettazione e la classificazione di risorse molto eterogenee». Si tratta di un progetto del 2011, che si legge all'indirizzo: http://www.culturaitalia.it/pico/thesaurus/4.3/thesaurus_4.3.0.skos.xml.
[37] https://commons.wikimedia.org/wiki/File:Culture_Datacloud.png.
[38] Andrejs Abele [et al.], Linking open data cloud diagram, Last version 2017, http://lod-cloud.net/. Non è privo di interesse notare che fra le categorie comprese nell'ultima versione del LOD cloud non sia presente il dominio cultural heritage.
[39] Il progetto SBN in LOD fa ben sperare nell'apertura, anche in Italia, dei dati catalografici (cfr. il documento elaborato dal gruppo di lavoro ICCU all'indirizzo http://www.iccu.sbn.it/opencms/export/sites/iccu/documenti/2015/LOD_SBN_scheda.pdf. Si veda la descrizione del progetto anche in: Margherita Aste; Maria Cristina Mataloni; Luca Martinelli, Linked data: il mondo di internet e il ruolo delle biblioteche, degli archivi e dei musei, «DigItalia», (2015), p. 65-73.
[40] Silvio Peroni [et al.], Semantic lenses as exploration method for scholarly article, «Communications in computer and information science», 385 (2014), p. 118-129.
[41] W3C, Resource description framework (RDF), 2014, https://www.w3.org/RDF/.
[42] W3C, Web ontology language (OWL), 2012, https://www.w3.org/OWL/.
[43] Marilena Daquino; Francesca Tomasi, Ontological approaches to information description and extraction in the cultural heritage domain. In: Humanities and their methods in the digital ecosystem, a cura di Francesca Tomasi [et al.]. New York: ACM, 2015.
[44] EDM, Europeana data model, http://pro.europeana.eu/page/edm-documentation/.
[45] Silvio Peroni; Francesca Tomasi; Fabio Vitali, Reflecting on the Europeana data model. In: Digital libraries and archives, 8th Italian research conference, IRCDL 2012. Bari, Italy, February 2012. Revised selected papers, a cura di Maristella Agosti [et al.]. Berlin-Heidelberg: Springer, 2013, p. 228-240.
[46] Un riferimento importante è: Martin Doerr, Ontologies for cultural heritage. In: Handbook on ontologies, a cura di Steffen Staab e Rudi Studer. Berlin-Heidelberg: Spinger, 2009, p. 463-486.
[47] Per un elenco si veda in particolare: W3C Incubator group report, Library linked data incubator group: datasets, value vocabularies, and metadata element sets, Last version 25 October 2011, https://www.w3.org/2005/Incubator/lld/XGR-lld-vocabdataset-20111025/. Altro strumento è il catalogo Linked open vocabularies (LOV), http://lov.okfn.org/dataset/lov/.
[48] L'ontologia è consultabile anche in visualizzazione HTML attraverso l'ambiente LODE (Live OWL documentation environment), http://dati.san.beniculturali.it/lode/.
[49] Silvia Mazzini; Francesca Ricci, EAC-CPF Vocabulary specification 1.1., 2011, http://archivi.ibc.regione.emilia-romagna.it/ontology/reference_document/referencedocument.html. L'ontologia EAC-CPF si può consultare invece all'indirizzo: http://labs.regesta.com/progettoReload/lontologia-eac-cpf/.
[50] OAD (Ontology of archival description) in Reload (Repository for linked open archival data). Reload è un progetto nato dalla collaborazione fra l'Archivio centrale dello Stato, l'Istituto dei beni culturali dell'Emilia Romagna e Regesta.exe per sperimentare le tecnologie del semantic web e dei linked open data nel dominio archivistico, in modo da ottenere una condivisione delle risorse archivistiche nel web e una loro integrazione con dati provenienti da altri domini. Il progetto si legge all'indirizzo: http://labs.regesta.com/progettoReload/oad-ontology/.
[51] ICOM/CIDOC Documentation Standards Group, Definition of the CIDOC conceptual reference model, January 2017, http://www.cidoc-crm.org/sites/default/files/2017-01-25%23CIDOC%20CRM_v6.2.2_esIP.pdf. Sul ruolo in particolare di CIDOC CRM come strumento per l'integrazione si veda: Maria Teresa Biagetti, Un modello ontologico per l'integrazione delle informazioni del patrimonio culturale: CIDOC-CRM, «JLIS.it», 7 (2016), n. 3, p. 43-77.
[52] Working Group on FRBR/CRM Dialogue, Definition of FRBRoo, Version 2.4 2015, http://www.ifla.org/files/assets/cataloguing/FRBRoo/frbroo_v_2.4.pdf.
[53] David Shotton; Silvio Peroni, Publishing roles ontology (PRO), 2013, http://purl.org/spar/pro.
[54] Timothy Lebo; Satya Sahoo; Deborah McGuinness, PROV-O: The PROV ontology, W3C Recommendation 30 April 2013, https://www.w3.org/TR/prov-o/.
[55] David Shotton; Silvio Peroni, CiTO, the citation typing ontology, 2015 http://www.sparontologies.net/ontologies/cito/source.html.
[56] EGAD, Expert Group on Archival Description, Records in context – conceptual model (RIC-CM), 2016, http://www.ica.org/en/egad-ric-conceptual-model-ric-cm-01pdf.
[57] ISDIAH, International standard for describing institutions with archival holdings, 2008, http://www.ica.org/sites/default/files/CBPS_2008_Guidelines_ISDIAH_First-edition_EN.pdf.
[58] ISBD, International standard bibliographic description, 2007, http://www.ifla.org/files/assets/cataloguing/isbd/isbd-cons_2007-it.pdf.
[59] FRAD, Functional requirements for authority data: a conceptual model, 2013, http://www.ifla.org/files/assets/cataloguing/frad/frad_2013.pdf.
[60] RDA, Resource description and access, 2015, http://www.rda-jsc.org/rda.htm. Sul ruolo di RDA come potenziale strumento per l'integrazione nel sistema beni culturali si veda: Federico Valacchi, Pezzi di cose nel mondo: il processo di integrazione delle descrizioni archivistiche nei sistemi interculturali, «JLIS.it», 7 (2016), n. 2, p. 333-369 (e in generale il vol. 7, n. 2, di JLIS).
[61] Regole italiane di catalogazione: REICAT, a cura della Commissione permanente per la revisione delle regole italiane di catalogazione. Roma: ICCU, 2009, http://www.iccu.sbn.it/opencms/export/sites/iccu/documenti/2015/REICAT-giugno2009.pdf.
[62] Già consistente è la letteratura sul lavoro condotto. Si veda in particolare: Ciro Gonano [et al.], Zeri e LODE: extracting the Zeri photo archive to linked open data: formalizing the conceptual model. In Digital libraries (JCDL). London: IEEE, 2014; Marilena Daquino [et al.], The Project Zeri photo archive: towards a model for defining authoritative authorship attributions. In Digital humanities 2016: conference abstracts. Kraków: Jagiellonian University & Pedagogical University, 2016, p. 472-474; Marilena Daquino; Francesca Tomasi, La Fototeca Zeri in linked open data, «AIB studi», 57 (2017), n. 1, p. 109-112; Marilena Daquino [et al.], Enhancing semantic expressivity in the cultural heritage domain: exposing the Zeri photo archive as linked open data, «Journal on computing and cultural heritage» (JOCCH), 10 (2017), n. 4, article 21. Cfr. anche: http://data.fondazionezeri.unibo.it/ sezione Documentation.
[63] Francesca Mambelli, Una risorsa online per la storia dell'arte: il database della fototeca Zeri. In: Digital humanities: progetti italiani ed esperienze di convergenza multidisciplinare, a cura di Fabio Ciotti. Roma: Università di Roma La Sapienza, Quaderni Digilab, 2014, article 7, http://digilab-epub.uniroma1.it/index.php/Quaderni_DigiLab/article/view/181.
[64] Si veda il dataset realizzato e la relativa documentazione tecnica: Fondazione Federico Zeri. Zeri photo archive RDF dataset, 2016, https://w3id.org/zericatalog/.
[65] ICCD, Normativa Scheda F, versione 2.00, http://www.iccd.beniculturali.it/index.php?it/473/standard-catalografici/Standard/9.
[66] ICCD, Normativa Scheda OA, versione 2.00, http://www.iccd.beniculturali.it/index.php?it/473/standard-catalografici/Standard/27.
[67] ICCD, Normativa BIB, versione 2.00, http://www.iccd.beniculturali.it/index.php?it/473/standard-catalografici/Standard/57.
[68] ICCD, Normativa AUT, versione 2.00, http://www.iccd.beniculturali.it/index.php?it/473/standard-catalografici/Standard/54.
[69] Marilena Daquino, OA entry ontology, 2015, http://purl.org/emmedi/oaentry.
[70] Marilena Daquino; Silvio Peroni, F Entry ontology, 2016, http://www.essepuntato.it/2014/03/fentry.
[71] F entry to RDF, https://dx.doi.org/10.6084/m9.figshare.3175273; OA entry to RDF https://dx.doi.org/10.6084/m9.figshare.3175057.
[72] SPAR ontologies, http://www.sparontologies.net.
[73] Marilena Daquino, Historical context ontology (HiCO), 2014 http://hico.sourceforge.net/index.html. Si veda anche: Marilena Daquino; Francesca Tomasi, Historical context (HiCO): a conceptual model for describing context information of cultural heritage objects. In: Metadata and semantics research. Berlin: Springer, 2015, p. 424-436.
[74] VIAF, Virtual international authority file, http://viaf.org/.
[75] Getty vocabularies, https://www.getty.edu/research/tools/vocabularies/.
[76] DBpedia, http://wiki.dbpedia.org/; DBpedia it, http://it.dbpedia.org/.
[77] Wikidata, https://www.wikidata.org.
[78] GeoNames ontology, http://www.geonames.org/ontology/documentation.
[79] Inge Reist [et al.]. An introduction to PHAROS: aggregating free access to 31 million digitized images and counting. Speech at CIDOC 2015 (New Delhi, September 5–9, 2015), http://network.icom.museum/fileadmin/user_upload/minisites/cidoc/BoardMeetings/CIDOC_PHAROS_Farneth-Stein-Weda_1.pdf.
[80] Il percorso che si illustra attraverso le figure 10-13, si basa sull'opera: Bonifacio de' Pitati, Scena di seduzione; Scheda n. 39890; Busta 0433. Pittura italiana sec. XVI. Venezia 9; Fascicolo 3. Bonifacio de' Pitati: soggetti profani, http://catalogo.fondazionezeri.unibo.it/scheda.v2.jsp?locale=it&decorator=layout_resp&apply=true&tipo_scheda=OA&id=44475&titolo=Pitati+Bonifacio+de%27+%28Bonifacio+Veronese%29%2C+Scena+di+seduzione.
{kind=link}