
Figura 1 – Tag 700/701 nell’UNIMARC
Alessandra Moi, Silvana Re, Francesca Verga
L’Università di Milano-Bicocca, fondata nel 1998, in trent’anni ha raggiunto dimensioni considerevoli: a fine 2021 ospitava 39.011 studenti e dottorandi, 1.269 tra professori e ricercatori, 849 tecnici e amministrativi, 416 assegnisti di ricerca.
La Biblioteca di ateneo è stata concepita fin dall’inizio come una singola istituzione, articolata fisicamente in tre sedi distinte (Medicina, Centrale e Scienze).
La sede Centrale della biblioteca ospita inoltre il Polo di archivio storico (PAST)1, che conserva i fondi archivistici di psicologi e psichiatri raccolti dall’ASPI - Archivio storico della psicologia italiana2 e tutti gli archivi storici acquisiti dall’Ateneo grazie a lasciti e donazioni.
I bibliotecari sono 37 ed è comune per una stessa persona occuparsi di più mansioni, a volte anche in sedi diverse: questo contribuisce a rafforzare la percezione della biblioteca come un organismo unico.
Tutte le sedi usano gli stessi software e le procedure di acquisizione, catalogazione e circolazione sono condivise, indipendentemente dalla localizzazione e dalla disciplina di appartenenza del materiale.
A fine 2020, il patrimonio della biblioteca era suddiviso come segue:
Fino alla gara (avviata il 9 giugno 2020), il posseduto della biblioteca è stato gestito con tre software diversi, oltre a strumenti di office automation come Microsoft Excel
Il software Aleph di Ex Libris3 gestiva l’acquisizione e la catalogazione del materiale a stampa, la circolazione e i servizi interbibliotecari. La catalogazione era basata sul formato UNIMARC. Per una scelta consapevole, il materiale elettronico non è mai stato catalogato in Aleph.
Il link resolver SFX4, sempre di Ex Libris, gestiva e-journal ed e-book dal punto di vista della copertura e dell’accesso, ma non aveva funzioni di acquisizione o catalogazione.
Gli acquisti di risorse elettroniche, comprese le banche dati, venivano quindi registrati in una serie di fogli di calcolo, mentre i record catalografici venivano scaricati dal sito dell’editore o da altre fonti, salvati in locale e convertiti in MARCXML basato su MARC21
La visibilità dell’intero posseduto era garantita dal discovery tool Curiosone, basato su EBSCO Discovery Service (EDS)5.
EDS conteneva sia record forniti da banche dati partner di EBSCO, relativi soprattutto ad articoli, sia record provenienti da caricamenti del nostro posseduto.
Questi ultimi erano automatici e giornalieri per quanto riguardava i record UNIMARC, mentre il materiale MARCXML veniva caricato manualmente dopo ogni acquisto oppure a scadenze fisse (in genere mensili), a seconda della tipologia di acquisizione (acquisto singolo o abbonamento).
In sede di configurazione si era deciso di mostrare agli utenti solo i record bibliografici effettivamente posseduti, usando un filtro basato su altri caricamenti automatici da Aleph e da SFX.
In aggiunta al materiale della biblioteca, i record provenienti dagli archivi PAST e ASPI e dal repository di Ateneo (Bicocca open archive, BOA6) venivano caricati automaticamente tramite il protocollo OAI-PMH7.
Nonostante l’assistenza fornita dai produttori dei software, la gestione di questi processi risultava molto onerosa: il posseduto digitale doveva essere tenuto aggiornato in più punti, i caricamenti automatici dovevano comunque essere monitorati e l’interfaccia del discovery tool richiedeva a sua volta aggiornamenti e manutenzione.
Infine, le statistiche delle varie risorse e servizi (in particolare le statistiche COUNTER) dovevano essere scaricate singolarmente e gestite con fogli di calcolo.
La scelta di passare a una library services platform (LSP)8 è quindi imputabile essenzialmente a due motivi:
Si è deciso quindi di cercare un software che permettesse di operare sempre in un unico ambiente, riutilizzando gli stessi dati catalografici, e che offrisse per la prima volta un ambiente di gestione delle risorse digitali integrato con quello delle risorse a stampa.
È noto che alcune di queste piattaforme non gestiscono il formato UNIMARC, ma solo il formato MARC21: si è ritenuto però che la difficoltà temporanea del cambio di formato fosse compensata dal fatto che MARC21 è il formato più diffuso a livello globale e viene aggiornato e manutenuto in maniera cooperativa da alcune tra le più importanti biblioteche di area angloamericana10.
A dicembre 2020 la gara è stata aggiudicata a OCLC11, che supporta solo MARC21. La biblioteca si è preparata quindi al cambio di formato12, tappa fondamentale della migrazione, che è iniziata con l’aggiudicazione efficace il 15 febbraio 2021 e si è conclusa a fine ottobre 2021, con la messa online del nuovo discovery.
Il primo tentativo di realizzare un formato machine-readable finalizzato allo scambio dei dati bibliografici va ricondotto al MARC pilot project, intrapreso dalla Library of Congress nel 1966 con la collaborazione di 16 istituti bibliotecari partecipanti, che si concluse con l’elaborazione del MARC II format nel 196813. La rapida diffusione del MARC come formato principale per lo scambio dei record, bibliografici e non, è da imputare alla sua rigorosa e complessa strutturazione, la quale permette di esprimere una grande quantità e varietà di informazioni attraverso l’utilizzo dei cosiddetti ‘campi’, funzionali alla codifica delle informazioni da parte delle macchine. Nonostante le indubbie differenze, i vari formati MARC rispondono a una medesima strutturazione, derivante dallo standard internazionale ISO 2709 e dal corrispettivo American national standard for information interchange ANSI/NISO Z39.2.
Nel formato MARC le informazioni sono organizzate in una successione di campi distinti nelle due diverse tipologie a lunghezza fissa e variabile, a loro volta ulteriormente articolati in una successione di etichette (tag), indicatori (indicator) e sottocampi (subfield).
Il MARC ha goduto e gode tuttora di larga fortuna essendo divenuto il formato in assoluto più utilizzato nella trasmissione delle informazioni bibliografiche. La presenza di centinaia di campi, dal 000 al 999, consente di strutturare informazioni complesse, di frammentarle e renderle elaborabili dalla macchina, a prescindere dalla loro formulazione in codici e standard catalografici specifici14. L’interoperabilità del dato ha garantito un costante riuso, con notevole profitto sia in termini di qualità dei dati stessi (acquisizione di dati provenienti da produttori autorevoli) sia di risparmio economico, favorendo la catalogazione derivata.
Pur partendo da una comune conformazione, i due formati UNIMARC e MARC21 sono contraddistinti da significative differenze che investono vari livelli: storico, gestionale e di strutturazione delle informazioni.
Per quanto riguarda la loro genesi storica, l’UNIMARC e il MARC21 non solo sono nati in periodi abbastanza distanti, ma altresì in virtù di esigenze significativamente diverse.
L’UNIMARC16 (Universal MARC format) venne pubblicato nel 1977 dall’IFLA con l’obiettivo di ricomprendere in sé i vari formati MARC a livello internazionale. L’UNIMARC è stato adottato in numerosi paesi europei, tra i quali l’Italia, ed è funzionale al trattamento dei record bibliografici e di authority, delle holding e dei dati di classificazione17.
La ‘nascita’ del MARC2118, invece, scaturì da una collaborazione tra la Library of Congress e la National Library of Canada, finalizzata all’armonizzazione tra i formati USMARC e CANMARC. Nel 1999 vennero pubblicati tutte e cinque i formati specifici che ancora oggi compongono il MARC21: Format for authority data; Format for bibliographic data; Format for classification data; Format for community information; Format for holdings data19.
UNIMARC e MARC21, per la loro diversa origine e il diverso ambito d’uso, sono quindi fortemente vincolati ai rispettivi approcci catalografici: europeo per l’UNIMARC, angloamericano per il MARC21.
Per questo motivo spesso si fatica a trovare un possibile allineamento sia nel significato, sia nella composizione dei campi e delle informazioni contenute. Tra le principali differenze si trovano20:
Figura 1 – Tag 700/701 nell’UNIMARC
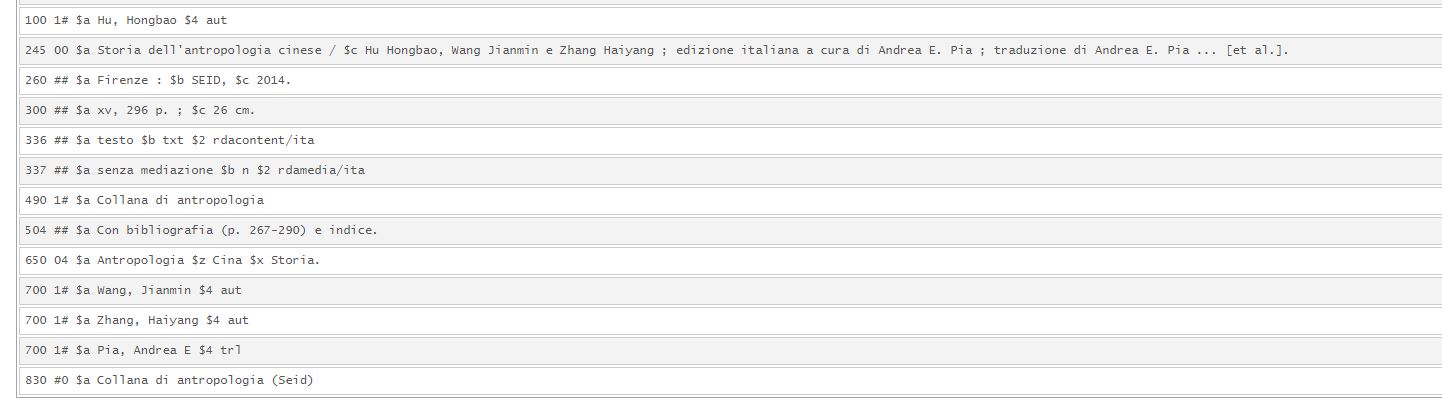
Figura 2 – Tag 100/700 nel MARC21

Figura 3 – Doppio tag 500 nell’UNIMARC
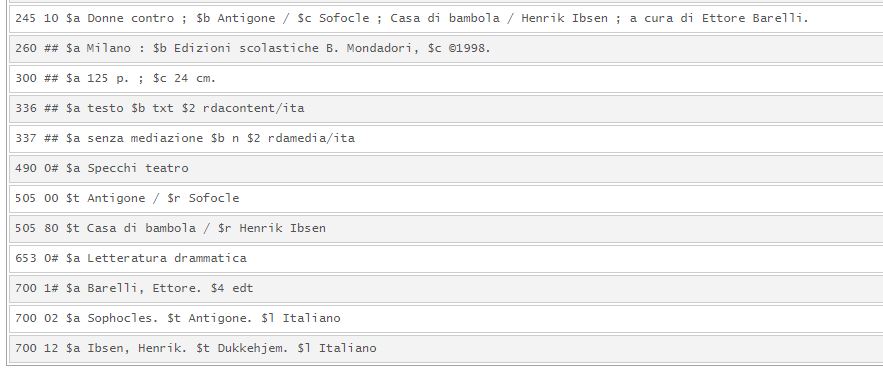
Figura 4 – Combinazione nome-titolo nel MARC21
Tali distinzioni, che sono assolutamente parziali rispetto al più ampio complesso di incongruenze tra i due formati, pongono delle sfide notevoli per chiunque si accinga ad attività di analisi, mappatura e migrazione tra i due formati.
Il passaggio verso un nuovo sistema gestionale richiede sia impegno ed energie sia consapevolezza delle differenze rispetto al contesto precedente. Nella transizione dal pregresso sistema Aleph a WorldShare Management Services (WMS) è stato necessario affrontare alcuni fondamentali cambiamenti, che non hanno investito il solo cambio di formato, bensì lo stesso approccio alle procedure catalografiche.
Al record bibliografico si aggiunge poi la sezione LHR (local holdings record), che contiene i dati della copia.
Mentre i dati contenuti nel master record possono essere modificati da qualunque partecipante a WMS, i record LBD e LHR sono accessibili alla sola istituzione che li ha creati.
In aggiunta a questi due aspetti, la biblioteca ha dovuto affrontare il ‘salto’ da un catalogo locale, totalmente gestito e gestibile in proprio, a un catalogo condiviso a livello globale, con la conseguenza di non poter gestire in piena autonomia i record bibliografici.
Ulteriore elemento di complessità è stato, infine, il cambio di formato da UNIMARC a MARC21, che ha richiesto un approfondito studio e un’ampia analisi dei metadati sia bibliografici sia di copia.
A dicembre 2018, ancora prima di pensare concretamente alla migrazione, la biblioteca aveva avviato una bonifica sui dati UNIMARC. La bonifica è stata svolta ancora in ambiente Aleph, parallelamente alle attività ordinarie, e si è conclusa a marzo 2021. Il suo scopo era non solo di facilitare una futura, eventuale migrazione, ma anche di garantire una certa coerenza interna al catalogo. La biblioteca infatti ha lavorato in Aleph/UNIMARC per circa vent’anni, in seguito a una migrazione da SBN avvenuta nel 2002: questo ha comportato una stratificazione delle scelte catalografiche. L’impostazione ereditata da SBN ha determinato i due interventi più significativi: la semplificazione delle monografie a livelli e la bonifica sui legami dei periodici.
Il lavoro sulle monografie a livelli è stato certamente il più complesso e ha richiesto diverse fasi di intervento. In primo luogo è stato necessario agire su tutte le catalogazioni a ‘tre livelli’ (record della monografia superiore, livello intermedio e livello inferiore), rimuovendo – tramite azioni in parte automatiche e in parte manuali – tutti i livelli intermedi e uniformando la catalogazione a soli due livelli. Inoltre sono stati eliminati tutti i record bibliografici con titolo non significativo (i cosiddetti “W” di SBN), preferendo l’utilizzo della nota di contenuto. Questo intervento è stato fatto anche nella consapevolezza che numerosi discovery tool e LSP non gestiscono correttamente le catalogazioni su più livelli. La scelta è stata così orientata al mantenimento della catalogazione a livelli solo in casi ben definiti, con una significativa revisione anche delle procedure catalografiche adottate.
Per quanto riguarda la bonifica dei legami sui periodici, l’attività ha interessato in particolar modo tutti quei legami orizzontali di successione o supplemento (esempio campi UNIMARC 430/440 e 421/422) importati dai reticoli di SBN, ma che all’interno di Aleph risultavano privi di significato in quanto non corrispondenti al posseduto della biblioteca. Si è dunque provveduto alla rimozione manuale di questi campi nei record individuati grazie ad apposite estrazioni.
ltre a questi due macrointerventi si sono poi aggiunte bonifiche più circoscritte, tra le quali la cancellazione, spesso automatizzata, di numerosi campi UNIMARC obsoleti o usati in maniera scorretta (esempio il campo UNIMARC 035 con l’indicazione del BID oppure il campo 791 per le forme varianti degli autori, entrambi importati da SBN). Interessante è stata invece la correzione, totalmente manuale, dei record bibliografici associati a un fondo personale acquisito dalla biblioteca. I record di questo fondo erano stati precedentemente importati tramite una procedura batch a partire da un minimale foglio di calcolo: per questo motivo erano privi di alcuni campi fondamentali, tra cui il Leader, e risultavano dunque invisibili agli utenti in quanto non gestiti dal discovery.
Tutte le attività di bonifica, dalla più complessa e faticosa fino alla più banale, hanno sicuramente agevolato il passaggio al nuovo formato: la partenza da una base dati relativamente coerente e omogenea si è, di fatto, rivelata fondamentale.
La definizione dei passaggi funzionali alla migrazione è stata portata avanti in stretta collaborazione con lo staff di OCLC e ha coinvolto il personale della biblioteca dalla stipula del contratto (aprile 2021) fino alla vera e propria entrata in produzione (ottobre 2021).
Il lavoro è stato articolato in una fase di pre-elaborazione e in una fase di caricamento dei dati.
La migrazione/importazione dei record bibliografici dal sistema Aleph/UNIMARC al sistema WMS/MARC21 è avvenuta attraverso il servizio di sincronizzazione, principalmente con le seguenti operazioni:
In base a queste funzioni la migrazione/importazione prevedeva come risultato due possibili scenari: l’aggiunta dei record bibliografici in WMS, se le notizie bibliografiche non erano presenti nel database (record added), oppure lo schiacciamento dei record importati su notizie bibliografiche già esistenti (record merged).
In generale, la mappatura dei campi del record bibliografico per cui era possibile fare un’equivalenza automatica (ad esempio il campo 200 UNIMARC che corrisponde inequivocabilmente al campo 245 MARC21) è stata eseguita interamente da OCLC. La biblioteca si è invece concentrata sulla mappatura di quei metadati che potevano essere gestiti in modo personalizzato, ovvero gli LBD, e sui record master di tipo added. A partire da queste importanti premesse si è proceduto alla lavorazione dei record.
La fase di pre-elaborazione ha visto due momenti ben distinti: una parte teorica sulla conversione del formato e l’individuazione delle possibili problematiche nell’importazione (aprile-luglio 2021) e una parte operativa di test di caricamento (settembre-ottobre 2021). Durante il momento di analisi teorica sono state prese numerose decisioni, alcune strategiche ai fini dell’importazione e altre più di carattere operativo.
Scelta di grande importanza è stata quella di non migrare in WMS i record che in Aleph non erano visibili agli utenti, ad esempio i record soppressi (disinventariati, smarriti ecc.) oppure i record cosiddetti on the fly, creati per le catalogazioni temporanee. Anche sui record di copia sono state prese delle decisioni analoghe, con l’esclusione dalla migrazione di copie non valide (disinventariate, smarrite, scartate, ordini non evasi ecc.).
Altrettanto significative sono state le decisioni che hanno coinvolto gli LBD, sezione a uso esclusivo della biblioteca. Tutti i dati che non avrebbero potuto essere di interesse per la comunità di OCLC sono stati infatti mappati sui dati bibliografici locali, ma è stata necessaria un’attenta valutazione per scegliere in quali campi LBD, standard o proprietari, inserirli.
Questa valutazione ha coinvolto, per esempio, le note all’esemplare su record di fondi personali (tag MARC21 596, 597, 598) e la Classificazione decimale Dewey.
Quest’ultima decisione, che ha visto l’inserimento della CDD nel tag MARC21 650, è stata particolarmente faticosa, perché inizialmente c’era una forte incertezza se posizionare in un campo di soggetto il numero della classificazione. Alla fine, tale soluzione è stata adottata per gli indiscutibili vantaggi: i numeri CDD corredati di vedetta sarebbero stati visibili in discovery e soprattutto ricercabili.
Tra le scelte di carattere operativo si annoverano, invece, una serie di azioni finalizzate al miglioramento qualitativo dei dati e al loro allineamento a pratiche in uso nel contesto OCLC, come per esempio l’eliminazione delle parentesi uncinate (< >) nelle qualificazioni.
In seguito alla fase di analisi i record bibliografici sono stati inviati a OCLC in blocchi per la pre-elaborazione vera e propria: i raggruppamenti sono stati definiti in base alle caratteristiche dei record stessi, dal blocco più omogeneo (record di monografie libro moderno) a quelli più particolari (record descrittivi di opere in più volumi o di miscellanee non editoriali, oppure del libro antico, oltre naturalmente al blocco di record descrittivi dei seriali).
Gli interventi di pre-elaborazione e di sincronizzazione sono stati descritti in un documento chiamato Scope statement che ha avuto sei versioni successive, a prova sia dei ragionamenti e delle riflessioni che man mano emergevano, sia della buona collaborazione che c’è stata con i colleghi italiani e olandesi di OCLC.
Lo Scope statement ha raccolto le scelte da operare sia sui metadati bibliografici sia su quelli delle copie ed è stato organizzato per sezioni di lavorazione:
Conclusa la fase di pre-elaborazione, è iniziata la fase di caricamento dei dati, durante la quale OCLC ha avviato le procedure di importazione e matching, allo scopo di trovare le corrispondenze con i record già presenti in WorldCat e non creare duplicati. Gli elementi usati per individuare le corrispondenze includevano:
Il matching implicava tre diversi risultati: nessuna corrispondenza e creazione del nuovo record (record added), corrispondenza trovata con conseguente schiacciamento (record merged), corrispondenze multiple su più record. In presenza di più di una corrispondenza, veniva avviata una nuova procedura, denominata ‘processo di risoluzione’, allo scopo di scegliere il miglior record sulla base di alcuni algoritmi, tra cui:
A conclusione della fase di sincronizzazione, i record venivano inviati alla convalida.
Non per tutti i record bibliografici il processo si è concluso con la convalida e il conseguente caricamento e visualizzazione su WMS. Si parla in questo caso di sparse record, ovvero di record non convalidati a causa di specifici errori a livello di struttura del formato MARC21: gli sparse record sono stati comunque caricati, ma sono invisibili agli utenti e richiedono una correzione manuale. A tale scopo, OCLC ha fornito un’apposita reportistica sui record sparse.
L’intero processo di migrazione è stato impegnativo: i record bibliografici trattati da OCLC sono stati 271.000. Non potendo scendere nel dettaglio di ogni decisione, fa seguito un breve approfondimento sulle due situazioni più complesse: la gestione delle opere in più volumi e i dati di copia. Le soluzioni finali adottate in questi due contesti hanno richiesto diversi momenti di riflessione.
Come si è detto in precedenza, la catalogazione a livelli era stata limitata, già prima della migrazione, a casi ben selezionati, preferendole soluzioni meno complesse, tra le quali l’uso della nota di contenuto.
Nel formato MARC21, la gestione dei legami verticali è garantita dal tag di relazione 773, corrispondente al tag UNIMARC 461; tuttavia, per una pratica interna definita dalla community di OCLC, il tag 773 non viene utilizzato a tale scopo all’interno di WMS.
Per questo motivo, gli unici record migrati con il legame 773 sono stati quelli del libro antico e delle miscellanee non editoriali: tuttavia, il campo di legame, privo della citazione del numero di sistema, non ha creato un reale collegamento tra i record, ma fornisce solo l’indicazione del titolo superiore in forma testuale.
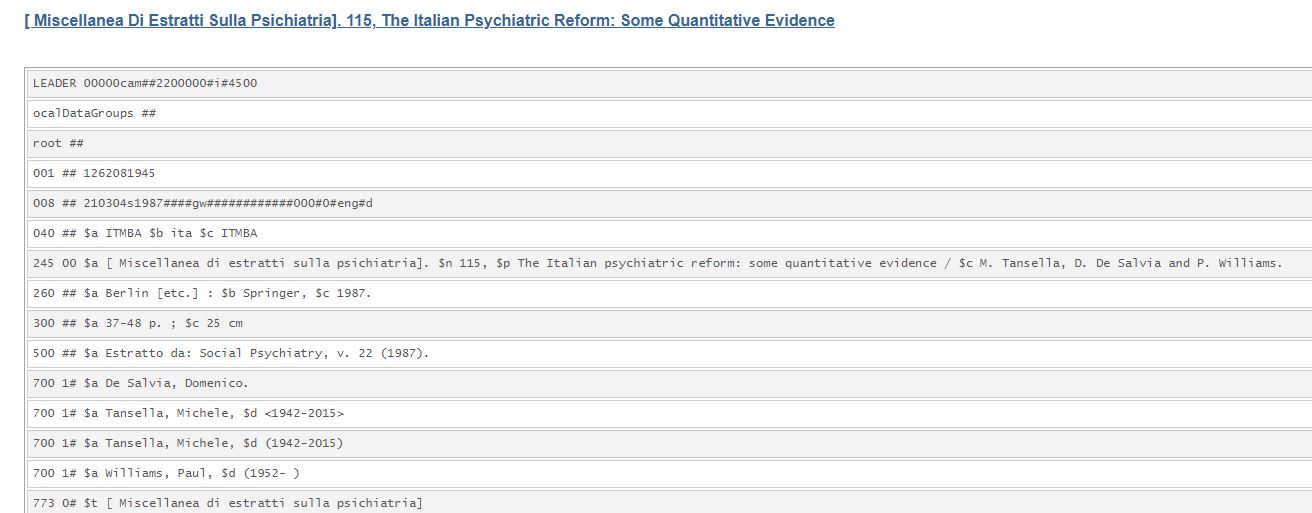
Figura 5 – Opera in più volumi con tag 773
Il trattamento dei restanti record multivolume è dipeso invece dalla presenza o meno dell’opera in WMS. I record merged, confluiti in record già esistenti, presentano descrizioni di tipo diverso: con il titolo della superiore nella collana, con legame nel tag 773, con titolo composto, con nota di contenuto.
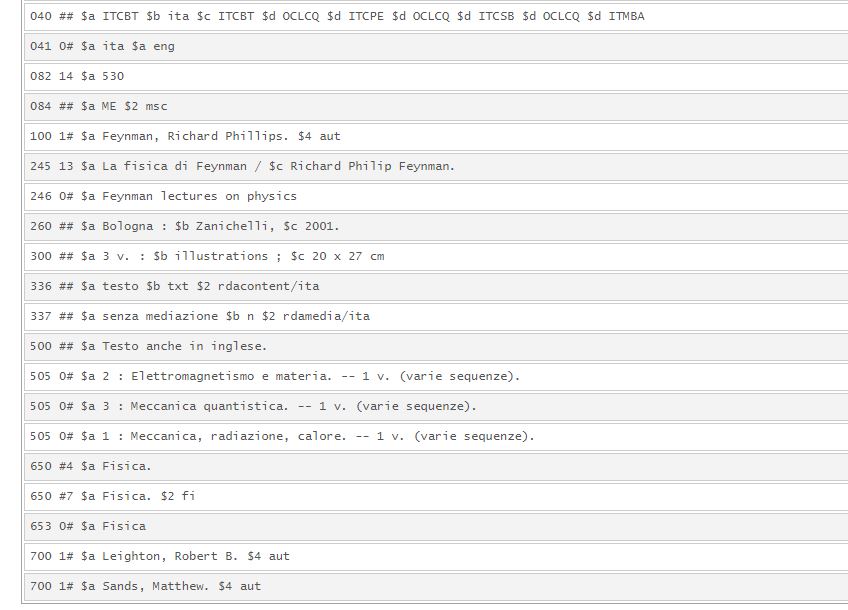
Figura 6 – Record merged on nota di contenuto
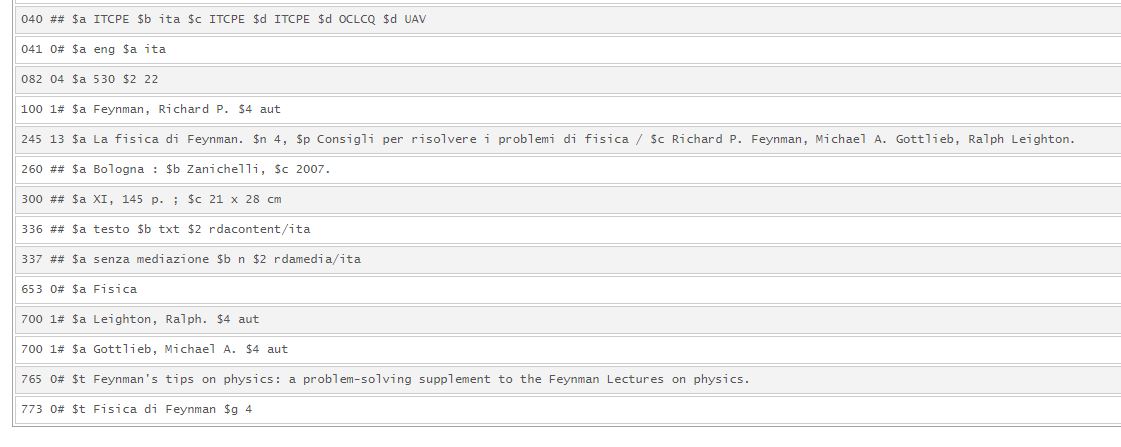
Figura 7 – Record merged con titolo composto e tag 773
I record added, non presenti in WMS, sono stati migrati con la struttura del titolo composto. Per questo motivo, i volumi di una stessa opera possono avere descrizioni non omogenee.
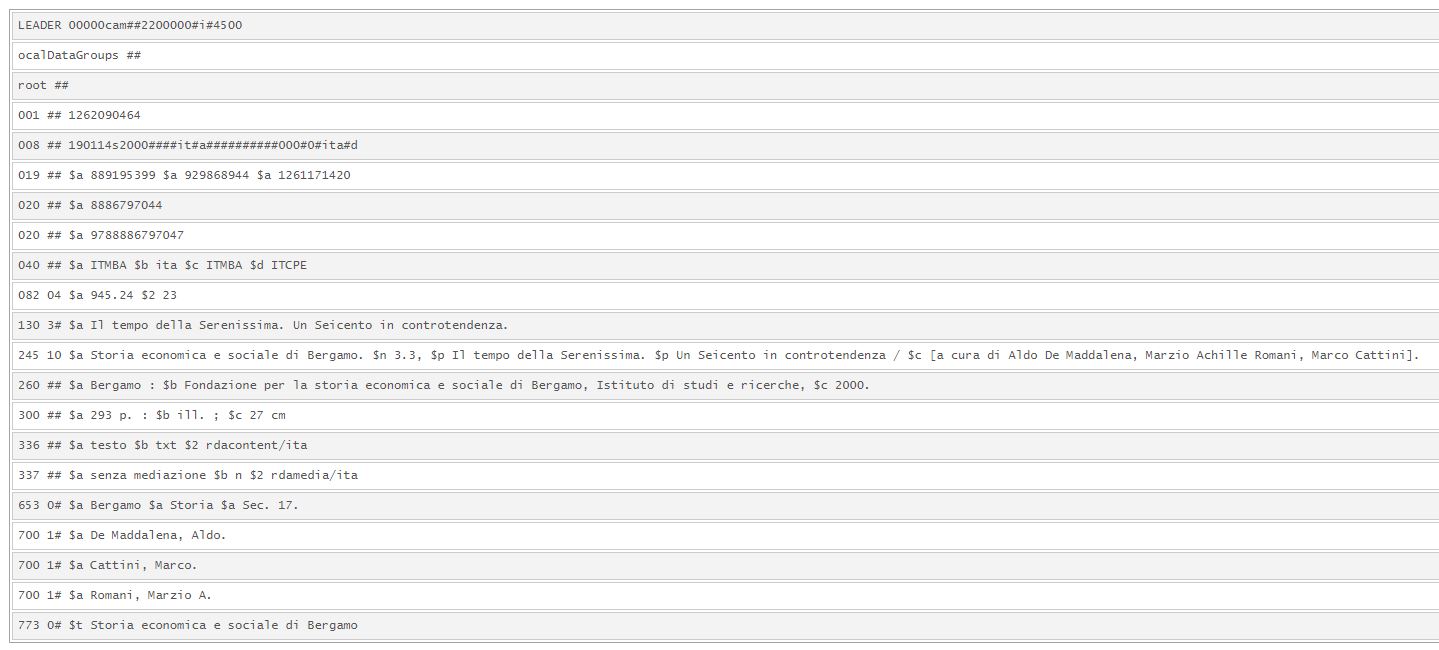
Figura 8 – Record added con titolo composto
Analogamente ai record bibliografici, anche i record di copia presentano delle significative differenze rispetto al precedente gestionale.
In primo luogo, in WMS i dati di possesso si articolano su due livelli: la holding (il posseduto della biblioteca) e il local holdings record (LHR), cioè i dati di collocazione. Ciò significa che un record bibliografico può essere contrassegnato come posseduto ma essere privo di LHR.
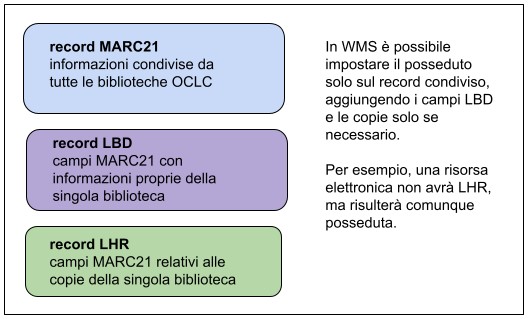
Figura 9 – Struttura tripartita del record in WMS
Il LHR in WMS può essere visualizzato in una duplice modalità: in visualizzazione testo e in formato MARC21. Aleph utilizzava l’UNIMARC per il record bibliografico e il MARC21 per il record di copia, ma offriva la visualizzazione dei dati di copia solamente tramite delle etichette parlanti, rendendo l’utilizzo dei campi MARC21 invisibile ai bibliotecari. Il passaggio a WMS ha quindi comportato l’apprendimento dei campi MARC21 delle holding, in aggiunta ai campi MARC21 bibliografici.
Si è resa necessaria un’apposita mappatura per i dati di copia (giugno-settembre 2021), di cui si riassumono di seguito alcuni aspetti significativi:
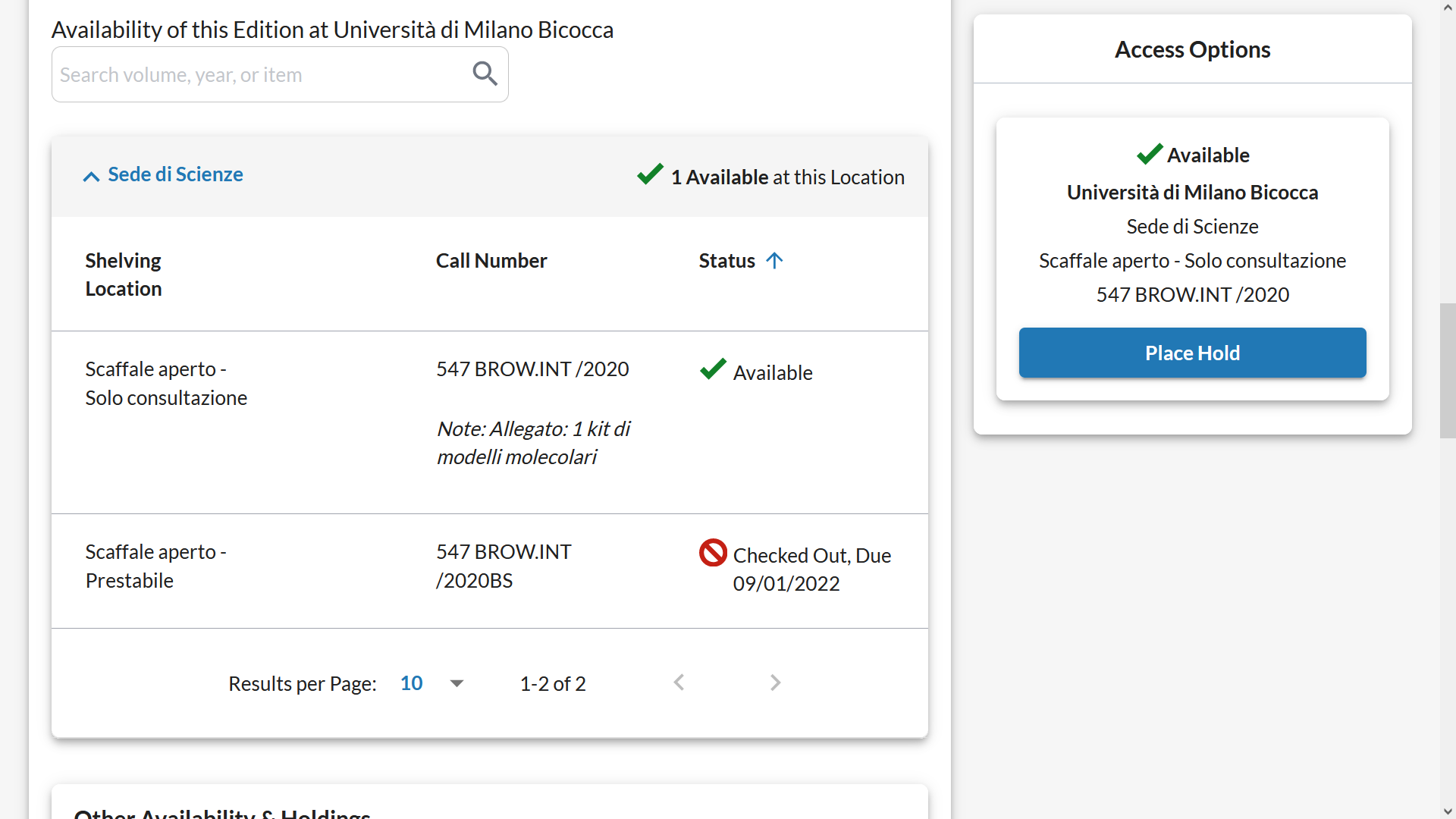
Figura 10 – Presenza di shelving location diverse per copie nella stessa sede
Le informazioni sullo stato di processo (ad esempio in catalogazione, smarrito, scartato ecc.) sono state assorbite in parte dalla shelving location e in parte dalle condizioni dell’ordine o dai dati della circolazione. Per esempio, “In legatoria” è diventata una shelving location.
La transizione da Aleph a WMS è stata piena di sfide, prima fra tutte l’adattarsi a un nuovo formato di catalogazione.
Il passaggio dal formato UNIMARC al formato MARC21 ha implicato un ripensamento notevole nella formulazione e articolazione di specifici dati e nell’approccio ad alcuni aspetti catalografici di primaria importanza. Per fare un esempio, la maggiore visibilità data all’autore principale nel formato MARC21 oppure la differente strutturazione dei campi per i titoli uniformi.
Se il passaggio a un nuovo formato è, di per sé, attività non facile né immediata, la contestualizzazione all’interno di un sistema complesso e con regole proprie come WMS ha richiesto un ulteriore ‘salto’: l’adeguamento del formato si è associato all’apprendimento di pratiche interne a cui è stato necessario uniformarsi. Ne sono un esempio il trattamento dei multivolume – che in WMS differisce dallo standard MARC21 – e la composizione del campo riservato alla Classificazione decimale Dewey. Il passaggio alla catalogazione condivisa ha quindi comportato la necessità di rinunciare al controllo sui dati offerto da un ambiente locale.
Allo stesso tempo, la vastità del database consente di trovare spesso record già catalogati, che è sufficiente localizzare o derivare, con un risparmio di tempo e di risorse; questo vale anche per le risorse elettroniche, che per la prima volta sono totalmente integrate in unico workflow di catalogazione e di acquisizione con le risorse a stampa.
Inoltre, la partecipazione a una comunità globale offre la possibilità di confrontarsi con i colleghi e di contribuire allo sviluppo dello strumento attraverso richieste di enhancement condivise.
Non ultimo, la presenza del nostro posseduto all’interno di WorldCat ci offre una grande visibilità a livello globale.
Dal punto di vista dell’utente, invece, il passaggio a WMS e a WorldCat Discovery si è tradotto in una migliore disponibilità dei vari formati di una risorsa (a stampa e in elettronico) e nella possibilità di estendere agevolmente la ricerca all’intero posseduto di WorldCat.
La situazione attuale compensa quindi ampiamente il lavoro richiesto dal cambio di formato.
Articolo proposto il 18 luglio 2022 e accettato il 6 settembre 2022.
Ultima consultazione siti web: 2 settembre 2022.