Figura 1 – Interrogazione di Wikidata (particolare)
Carlo Bianchini, Andrea Marchitelli, Alessandra Moi
Se si vogliono indagare gli sviluppi più recenti della biblioteconomia e della bibliografia italiane, facendone emergere i temi, le linee di sviluppo, le tendenze, i protagonisti e valorizzando, in ultimo, la produzione scientifica nazionale, è indispensabile disporre di dati bibliografici completi e aggiornati.
Gli autori di questo studio hanno quindi deciso di procedere alla creazione di una banca dati bibliografica relativa alla produzione scientifica di ambito biblioteconomico in Italia, a partire dalle riviste di settore, che sono la sede più propria del dibattito e lo strumento più adatto a individuare le linee di sviluppo disciplinari e professionali.
Allo stato attuale, infatti, gli strumenti bibliografici disponibili per la letteratura biblioteconomica italiana sono sostanzialmente due: BIB. Bibliografia italiana delle biblioteche, del libro e dell’informazione di Alberto Petrucciani, Vittorio Ponzani e Giulia Visintin, con un CD-ROM allegato che copre l’arco temporale dal 1971 al 2004, e con una versione in linea per il periodo 1992-20011, e la rubrica Letteratura professionale italiana pubblicata annualmente dal 1975 dapprima sul Bollettino AIB e poi su AIB studi, da Alberto Petrucciani e Vittorio Ponzani, e sulla quale si basa la banca dati citata.
Per un’elaborazione dei dati più facile e rapida sarebbe preferibile disporre di dati in formati trattabili in modo automatico, ma il formato con il quale sono disponibili i dati di questi preziosi e unici strumenti bibliografici rende complessa ogni possibile elaborazione di questo tipo. La banca dati BIB è infatti disponibile su un CD-ROM che richiede hardware e software sempre più difficilmente reperibili; la sua versione online, oltre a essere cronologicamente limitata, non è neppure più raggiungibile in linea2; la rubrica annuale è disponibile al pubblico solo in versione cartacea e non ha una cumulazione pluriennale.
I dati da raccogliere dalle riviste di settore per svolgere accurate analisi bibliometriche sono diversi e raggruppabili in quattro tipologie:
Gli articoli pubblicati sulle riviste italiane di biblioteconomia sono davvero molti (la sola rivista Biblioteche oggi, per esempio, ne conta oltre 4.500 nell’arco di tempo dal 1993 al 2020) e, come si è visto, devono essere integrati con i dati relativi agli autori - persone ed enti - ai concetti e agli altri oggetti bibliografici collegati. Perciò per il progetto si è reso indispensabile individuare uno strumento molto potente per la registrazione, gestione e analisi dei dati, bibliografici e non.
A tale scopo è stato scelto come strumento di lavoro Wikidata4: si tratta di un database libero, collaborativo e multilingue che raccoglie in modo centralizzato dati strutturati per fornire supporto ai progetti di Wikimedia (per esempio Wikipedia, Wikimedia Commons, Wikisource ecc.). Wikidata, tuttavia, fornisce supporto anche a molti altri siti e servizi del web, grazie al fatto che il contenuto di Wikidata è disponibile sotto licenza libera, è esportabile usando formati standard e può essere facilmente interconnesso ad altri insiemi di dati aperti. Un altro punto di forza di Wikidata è quello di essere una base di conoscenza che può essere letta e modificata allo stesso modo da umani e macchine.
Oltre a questi interessanti e rilevanti aspetti, Wikidata si presenta anche come un hub, cioè uno strumento che, sulle entità che descrive, raccoglie informazioni di qualità e provenienti da fonti diverse; ciò avviene attraverso il raggruppamento o cluster5 di identificatori (ID) provenienti dal web semantico che viene creato in una delle quattro parti della descrizione di un item previste da Wikidata. Infine, ma non meno importante, essa è uno strumento gratuito a disposizione di tutti.
I vantaggi dell’utilizzo di Wikidata come dataset per la creazione, elaborazione e condivisione dei dati sono numerosi. Wikidata, infatti, consente di migliorare o mettere in atto numerose funzioni di essenziale importanza: l’identificazione delle entità (entity management), l’arricchimento attraverso il riuso di dati provenienti da fonti diverse, l’integrazione di dati provenienti da tali fonti. Tutto ciò garantendo la qualità, l’indipendenza dei dati da hardware e software, la loro accessibilità come presupposto per la loro condivisione e interoperabilità, il decentramento del lavoro di creazione e gestione attraverso la modularità, la possibilità di riuso da parte di terzi, la visualizzazione di tutti i dati tramite strumenti grafici e la loro analisi. Un aspetto altrettanto importante per un progetto scientifico è che Wikidata consente di indicare la fonte di ogni singolo dato relativo a un’entità (per esempio indicando una fonte sulla quale si trova la data di nascita di una persona e un’altra che ne riporta la data di morte; oppure due fonti che riportano date di nascita o di morte divergenti, documentando l’origine di uno specifico dato).
Tuttavia, ai fini del progetto di creazione dei metadati relativi alle riviste italiane di biblioteconomia su Wikidata, come strumento per indagare gli sviluppi più recenti della biblioteconomia e della bibliografia italiana, alcune funzioni offerte da Wikidata come insieme di dati in formato LOD sono particolarmente interessanti: l’identificazione, la visualizzazione e l’analisi e, infine, il riuso.
Un processo fondamentale nel lavoro con i dati bibliografici è l’identificazione degli autori. Le grandi banche dati citazionali commerciali - come Scopus o Web of science - solo di recente, con l’aiuto di identificatori come ISNI e ORCID, hanno iniziato ad affrontare il problema dell’ambiguità nell’identificazione degli studiosi di cui avevano sempre sofferto6. Wikidata prevede invece che oltre ai dati descrittivi (proprietà) relativi a un item, si registrino nel modo più sistematico possibile anche gli identificatori di altri servizi. Perciò un item relativo a una persona si può collegare contemporaneamente alla rappresentazione di quella medesima entità descritta in molti altri servizi, come i cataloghi delle biblioteche nazionali, o i fornitori di identificatori per i ricercatori come ORCID, VIAF, ISNI, con gli IRIS e altri depositi istituzionali e i social come LinkedIn, Twitter, Facebook, ResearchGate ecc. Grazie al collegamento di molti identificatori a un item, quando i dati relativi agli autori di una certa rivista vengono collegati con Wikidata, diventa possibile identificare quell’autore a vantaggio di quella specifica rivista di partenza, ma anche per tutte le altre riviste in cui ha eventualmente pubblicato e tutti gli altri servizi del web in cui è identificato (per esempio, l’IRIS dell’università a cui afferisce).
È questo che si intende quando si parla di Wikidata come un «hub del web semantico»7. La registrazione degli ID di molti dataset all’interno di un singolo item garantisce che, in fase di esplorazione e analisi dei dati, le interrogazioni al sistema abbiano due caratteristiche fondamentali per ogni sistema di recupero dell’informazione, ovvero precisione e richiamo.
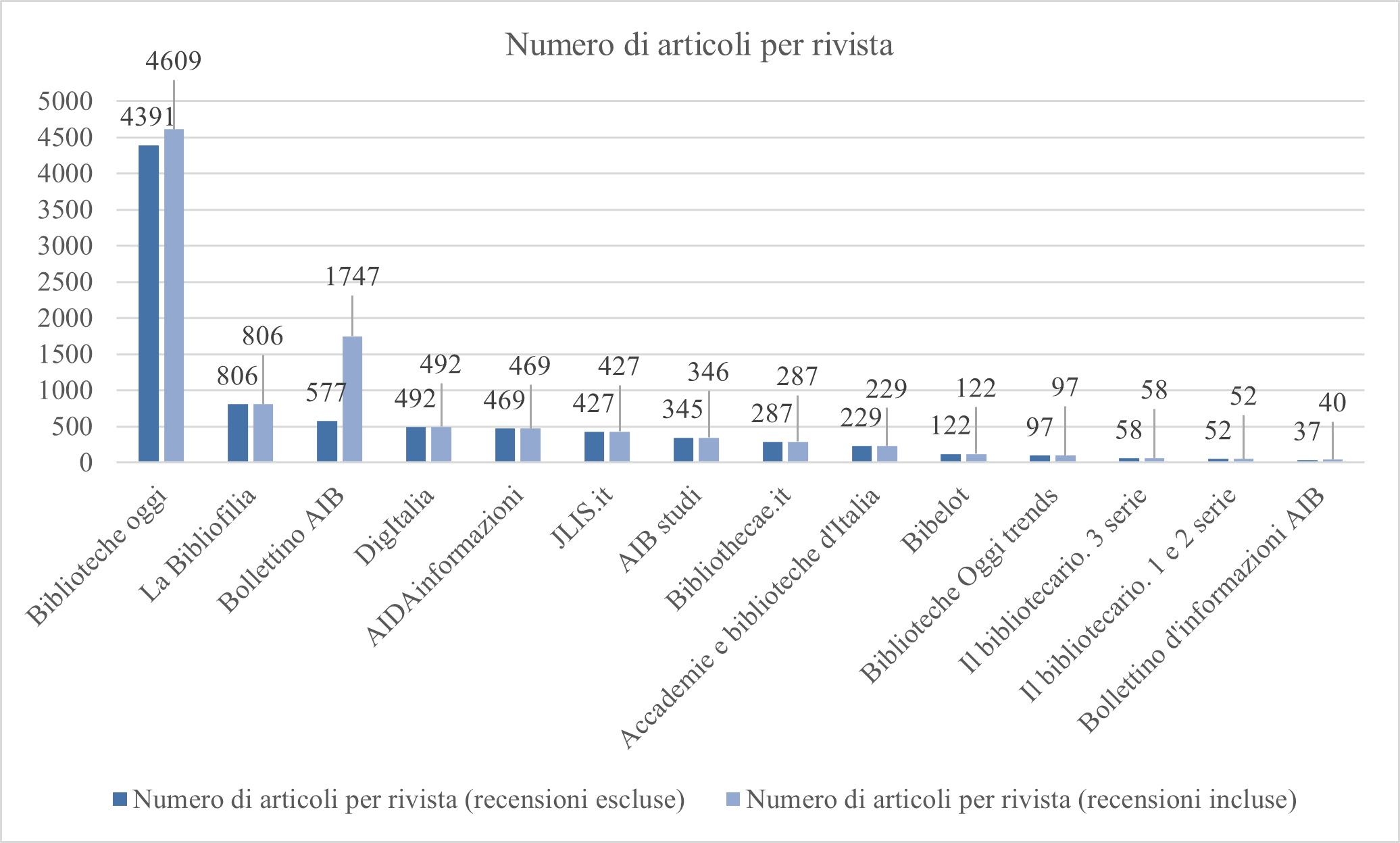
In Figura 1 si può vedere un’applicazione concreta del processo di identificazione in Wikidata. Per ogni ‘Silvia Pellegrini’ finora individuata e inserita in Wikidata, esiste un item dedicato e opportunamente distinto e descritto; a ciascuno di questi item vengono aggiunti gli identificatori di ciascuna diversa entità. Le proprietà descrittive di ciascun item in Wikidata consentono l’identificazione di Silvia Pellegrini all’interno di Wikidata, gli identificatori esterni collegati a quell’item consentono l’identificazione di quella entità negli altri dataset del web semantico8.
Figura 1 – Interrogazione di Wikidata (particolare)
Wikidata offre anche un secondo vantaggio molto rilevante per gli sviluppi del progetto, che consiste nella possibilità di analizzare, anche visivamente, i dati relativi alle pubblicazioni in modo più complesso di quando non si possa fare attraverso i normali strumenti bibliografici. Da quando è nato, nel 2012, Wikidata è sempre più utilizzato come strumento per la pubblicazione di dati bibliografici e fonte per la loro analisi.
Uno dei tool più noti che utilizzano i dati di Wikidata ai fini di analisi bibliometriche è Scholia9, creato da Finn Årup Nielsen. Lo scopo del sito è creare profili istantanei – e quindi sempre aggiornati grazie ai dati presenti su Wikidata – per diversi possibili oggetti di interesse: singoli ricercatori, organizzazioni (come un dipartimento universitario o un istituto di ricerca), riviste accademiche, editori, singole opere scientifiche e argomenti di ricerca10.
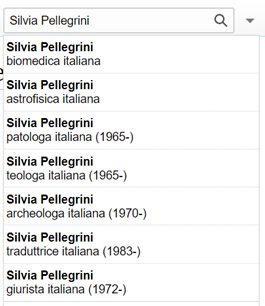
Per esempio, Scholia permette di ottenere un elenco di tutte le pubblicazioni di un ricercatore (come fa un normale catalogo), ma offre anche molti altri punti di vista pronti per un’analisi approfondita (Figura 2): mostra un grafico con il numero delle pubblicazioni per anno (Figura 2.1) e un altro grafico con il numero di pagine pubblicate per anno (Figura 2.2; infatti una monografia è più impegnativa da produrre rispetto ad alcuni articoli, ma essendo rappresentata nel primo grafico da una sola pubblicazione, potrebbe mostrare una flessione nella continuità del lavoro che in realtà non c’è stata). Offre una visualizzazione tabellare, ma anche un grafico (Figura 2.3), con gli argomenti più trattati da quell’autore e una rappresentazione a grafo delle persone con cui collabora (Figura 2.4) ecc.
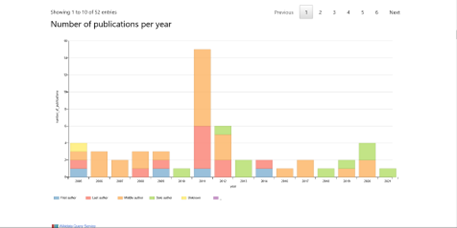
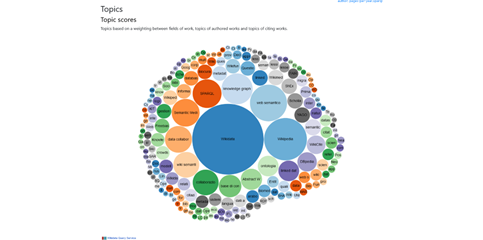

Figure 2.1/2.4 – Alcune visualizzazioni dei dati bibliografici ottenute con Scholia
Un terzo vantaggio offerto dal ricorso a Wikidata per il progetto – e ultimo a essere menzionato in questa rassegna limitata per ragioni di spazio – è la possibilità di riuso dei dati. Pubblicare i dati su Wikidata aumenta la loro visibilità e reperibilità ma potenzialmente anche il loro utilizzo semplice, libero e gratuito da parte di terzi, cioè da parte di altri servizi del web semantico, per i propri scopi. La Figura 3 mostra un esempio di come il Catalogo della biblioteca della Pontificia Università della Santa Croce possa offrire un box informativo su un autore (Umberto Eco) riutilizzando e visualizzando i dati presenti e disponibili su Wikidata (e sul VIAF)11.
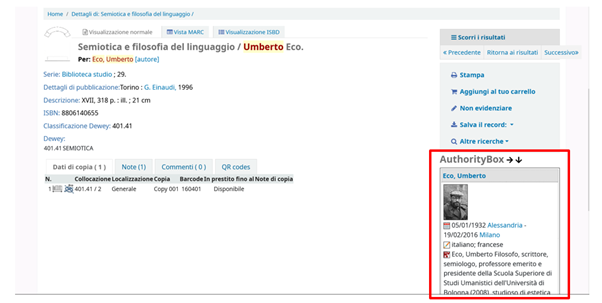
Figura 3 – Esempio di riuso di dati Wikidata nell’AuthorityBox del Catalogo PUSC
Dal momento che l’esito dell’analisi della produzione di un ricercatore, di un dipartimento, di una rivista ecc. attraverso Wikidata o Scholia dipende strettamente dalla disponibilità dei dati di partenza su Wikidata stessa, per sviluppare il progetto di indagine sugli sviluppi più recenti della biblioteconomia e della bibliografia italiana era indispensabile in via strumentale procedere al caricamento di tutti i dati necessari su Wikidata.
Si tratta di un lavoro problematico e complesso per diverse ragioni. Prima di tutto la disponibilità difforme dei dati di partenza: i dati si possono trovare in formati digitali più o meno accessibili e riutilizzabili (per esempio, in formato PDF o CSV) o essere disponibili in solo formato cartaceo (come si è visto). In secondo luogo, i dati possono non essere omogenei, sia all’interno della stessa rivista (registrazione non uniforme dei nomi e delle parole chiave, eterogeneità nei formati disponibili per lo scarico) sia tra riviste diverse. In terzo luogo, il caricamento dei dati su Wikidata può avvenire con procedimenti diversi: semplificando in modo estremo, si può procedere in modo manuale (registrando un dato per volta), in modo semi-automatico (registrando un blocco di dati per volta e procedendo in seguito al loro miglioramento) o in modo automatico (e procedendo poi al loro controllo)12.
Il caricamento dei dati bibliografici su Wikidata ha quindi posto diverse questioni: considerata la complessità della procedura, esiste un metodo preferibile per procedere al caricamento dei dati? Esistono metodi, strumenti e tecniche per il controllo dei dati? Ne esistono per facilitare l’identificazione degli autori? E per l’arricchimento degli item (cioè un’entità descritta) in Wikidata? Quale modello cooperativo si può mettere in atto per fare in modo che il processo di aggiornamento dei dati bibliografici si sostenga nel tempo? Esistono procedure per migliorare i dati citazionali? I dati citazionali ottenibili sono comparabili con quelli di altri strumenti citazionali, almeno per quanto riguarda la situazione italiana?
Prima di approfondire la più complessa questione relativa alle modalità di caricamento dei dati, risulta utile chiarire alcuni passaggi preliminari che si sono rivelati fondamentali per la corretta impostazione del lavoro. In primo luogo, il censimento puntuale di tutte le riviste italiane di biblioteconomia, cessate e/o attive.
Questa ‘rassegna’ ha costituito una base di partenza imprescindibile, basti pensare che ciascuna rivista italiana si basa su diverse modalità di conservazione e strutturazione dei dati e offre sistemi di interrogazione più o meno aperti verso l’esterno. A partire da un’apposita query di Wikidata13, sono state individuate 25 riviste di biblioteconomia afferenti al contesto italiano: per ciascuna rivista si è poi deciso di stabilire una priorità per il caricamento sulla base dell’autorevolezza, ma anche del periodo di attività, della rivista14. I criteri di scelta della priorità sono stati anche determinati dalla relativa maggiore fattibilità del caricamento dei dati e non rispecchiano assolutamente una valutazione di ordine gerarchico o qualitativo delle riviste stesse.
Il secondo passaggio è stato definire il modello logico dei dati, cioè un’ontologia di riferimento per il progetto. Si è trattato cioè di: individuare chiaramente quali entità, ovvero item, sarebbero state oggetto delle attività di caricamento e successivo arricchimento; stabilire quali dati, espressi sotto forma di proprietà, si sarebbero dovuti associare a ciascuna entità; stabilire il livello minimo di completezza potenzialmente raggiungibile. Trattandosi di un progetto finalizzato alla valorizzazione disciplinare della biblioteconomia italiana attraverso le riviste e le pubblicazioni di settore, gli item di principale interesse sono stati logicamente individuati in: articoli di ciascuna rivista, autori a essi associati, riviste italiane individuate, parole chiave degli articoli.
In tutti i casi, si tratta di entità molto ben definite e documentate in Wikidata, per le quali sono già state rese disponibili un’ampia serie di proprietà: in particolar modo per gli articoli e per gli autori è stata fatta una precisa selezione, volta a individuare tutte quelle proprietà giudicate imprescindibili ai fini di una corretta identificazione degli item. Tali liste sono mantenute e messe a disposizione della comunità15.
Per gli articoli, le principali proprietà individuate come tali – oltre all’etichetta (label), che è il nome in linguaggio umano, la descrizione e le eventuali forme varianti del nome16 – sono state:

Figura 4 – Esempio di articolo con relative proprietà, visualizzato tramite Reasonator17
L’analisi del lavoro di caricamento dei dati relativi agli autori ha mostrato la differenza tra un approccio orientato alle entità e quello tradizionalmente orientato alla registrazione degli oggetti di interesse catalografico. Si tratta di una differenza che si può rilevare già nella prima edizione di RDA (Resource description and access), lo standard di metadatazione internazionale derivato dalla trasformazione delle AACR218. Anche se i dati che si registrano sono sostanzialmente i medesimi, muta l’approccio concettuale. L’autorialità, infatti, è solo uno dei possibili aspetti con i quali è possibile descrivere una persona e, assumendo un diverso punto di vista focalizzato sull’entità, ci si colloca in una prospettiva nella quale una persona non è necessariamente un autore. Perciò un autore è, prima di tutto, una persona o un ente (per esempio, una famiglia o una istituzione) in grado di agire. In questo senso, è un agente, cioè «un’entità capace di azioni intenzionali, di godere di diritti e di essere ritenuta responsabile delle proprie azioni»19. Un agente può svolgere attività anche molto differenti tra loro che lo qualificano per esempio, di volta in volta, come autore (in molti possibili ruoli come autore principale o secondario, curatore, traduttore, prefatore ecc.), editore, proprietario, pittore, scultore, restauratore, fornitore ecc. Le proprietà di norma attribuite a una persona nelle anagrafi a esse destinate sono relative alla sua essenza (nome e cognome, data e luogo di nascita, sesso, lingua e nazionalità e così via) e, in misura proporzionata, alle sue attività (di autore ecc.). È evidente che le proprietà attribuibili all’essenza della persona saranno quelle di maggiore interesse per la generalità dei servizi del web semantico (potranno interessare biblioteche, ma anche archivi, musei e altre istituzioni culturali e di diversa natura) mentre i dati relativi all’attività di autore, supponiamo, saranno di interesse primario per le biblioteche20.
Perciò, gli autori rientrano in Wikidata nella più vasta categoria degli ‘umani’ (il termine utilizzato in Wikidata per identificare l’entità persona), ai quali, come si potrà immaginare, è possibile attribuire svariate decine di proprietà. A fronte di questo, le informazioni di norma fornite dalle riviste sugli autori sono estremamente ridotte: solo di recente si è consolidata la prassi di registrare affiliazioni e altri dati rilevanti come l’ORCID.
Per questo motivo, si è scelto di optare inizialmente per un numero minimo di attributi - da registrare se disponibili sulle fonti utilizzate - con l’idea passare a una successiva attività di arricchimento manuale in una seconda fase del progetto:
Di queste proprietà, solamente le prime quattro sono state considerate obbligatorie.
Non è stato quasi mai necessario creare gli item delle riviste, già esistenti su Wikidata. Le più importanti proprietà associate alle riviste sono riassunte nell’apposito template dedicato alle bibliographic property21, tra cui quelle essenziali possono essere individuate in:
Ben diversa e più impegnativa, invece, è stata la gestione delle parole chiave. La principale differenza rispetto alla procedura applicata per gli item di articoli, autori e riviste, è che per l’inserimento delle parole chiave si è scelto di non procedere necessariamente alla creazione dei relativi item in Wikidata.
In Wikidata non esistono item la cui proprietà “istanza di” abbia come valore “parola chiave”, “termine di soggetto”, “stringa di soggetto” o simili. Che un concetto sia soggetto di un’opera, infatti, è una questione ‘relazionale’ e non ‘ontologica’: i soggetti non esistono in forma a sé stante, ma qualunque oggetto o concetto rappresentato da un item può essere soggetto di una pubblicazione, rappresentata da un altro item, stabilendo tra i due una relazione “è soggetto di”. Questo approccio deriva dal modello logico che Wikidata adotta per esprimere il soggetto: si tratta di una relazione tra due item, nella quale la qualifica di soggetto è espressa dalla proprietà P921 (“main subject”). Tale modello è in perfetta sintonia con quello di IFLA LRM, nel quale si prevede una relazione “has as subject” (LRM-R12) per collegare un’opera a una res. Un esempio concreto, preso dall’attività che abbiamo condotto all’interno del progetto, è quello dell’item “bibliotecario” (Q182436), spesso utilizzato come parola chiave negli articoli biblioteconomici; l’item in questione è una istanza di “professione” e non una parola chiave o un soggetto in sé. È solo la relazione con gli articoli - espressa dalla proprietà “argomento principale” (P921) - che ne certifica in quello specifico caso la funzione di parola chiave.
All’interno di questo progetto, la decisione di non creare gli item utilizzabili come parole chiave è stata dunque motivata dalla complessità di individuare di volta in volta la tipologia di item corretta e le relative proprietà; questa attività avrebbe certamente portato a un aggravio del lavoro e a un allungamento complessivo dei tempi. Il legame tra parole chiave e articolo è stato quindi valorizzato solo quando esisteva già un item per quel concetto, senza doverlo creare.
Dopo aver definito gli item da creare e le relative proprietà, è iniziata la fase di ricerca di una metodologia di lavoro che fosse la più rapida e semplice possibile, e la più facilmente replicabile. Questo obiettivo non era banale, perché in conflitto con la grande eterogeneità di sistemi, anche tecnologici, ai quali ciascuna rivista si affida per la pubblicazione e l’accessibilità dei propri dati.
Il punto di partenza è stato la messa alla prova di metodi già sperimentati in progetti analoghi. Il primo esempio risale al 2019, quando Alessandra Boccone e Remo Rivelli pubblicarono i risultati del primo caricamento in Wikidata di dati bibliografici provenienti da una rivista online di area italiana, ovvero Bibliothecae.it22. Il processo di caricamento, che è tuttora utilizzato dal gruppo redazionale di Bibliothecae.it, prevede un sistema semi-automatizzato, in cui alla creazione manuale degli autori segue il caricamento degli articoli da Zotero a Wikidata tramite il tool Zotkat23. Sono tuttavia necessari interventi manuali per l’inserimento delle citazioni bibliografiche originali in Zotero, per la creazione delle relazioni (per esempio, tra l’item dell’articolo con dati provenienti da Zotero e l’autore precedentemente creato manualmente) e per la necessaria revisione dei dati caricati24.
Considerata la significativa componente di lavoro manuale, il flusso di lavoro utilizzato da Bibliothecae.it risultava poco adatto alla grande mole di dati che si prevedeva sarebbe stato necessario caricare su Wikidata.
Si è perciò proceduto alla ricerca di strumenti tramite i quali gestire grandi quantità di dati e che offrissero anche moduli di integrazione con Wikidata. L’unico strumento che al momento consentiva azioni di import/export massivo verso grandi dataset di autorità era OpenRefine25.
Il problema successivo era avere a disposizione i dati degli articoli in un formato adatto a essere utilizzato con OpenRefine (OR).
Dopo alcuni tentativi di web scraping26 – un approccio che dava risposte molto eterogenee dovute alle differenti modalità di creazione dei siti web delle riviste di interesse – la soluzione vincente è stata, in questo caso, quella di sfruttare le potenzialità del software gestionale in uso presso un buon numero di riviste, ovvero OJS (Open Journal System)27, che prevede l’esposizione dei metadati pubblicati dalla rivista tramite il protocollo OAI-PMH28. L’adesione alla Open Archives Initiative delle riviste ad accesso aperto, inoltre, permette che tali metadati siano messi a disposizione attraverso licenze copyleft a diversi gradi di apertura, tali da consentirne il riuso.
Il protocollo OAI-PMH, interrogabile direttamente tramite OR, ha permesso di ottenere in maniera semplice e veloce i metadati completi degli articoli per le riviste JLIS.it, AIB studi, Biblioteche oggi e Biblioteche oggi trends, secondo una procedura che, in seguito a vari cicli di elaborazione e riflessione, può essere riassunta nei seguenti punti fondamentali29:
Non sempre tali passaggi si sono svolti in maniera lineare; in alcuni casi, a seconda della rivista trattata, si è reso necessario effettuare più cicli di importazione tramite il protocollo OAI-PMH, il quale è in grado di gestire più formati per l’esposizione dei metadati. Solitamente, quando presente, si è utilizzato il formato NLM (National Library of Medicine), perché forniva i dati più completi, ricchi e altamente strutturati, oppure in alternativa il formato OAI DC (in genere più carente poiché basato su Dublin Core simple).
Per ottenere i dati delle riviste che non prevedono l’utilizzo di OJS, essendo spesso periodici dalla grande tradizione e importanza scientifica e indispensabili per raggiungere le finalità del progetto (per esempio, Accademie & biblioteche d’Italia o AIDAinformazioni) si è deciso di contattare direttamente gli editori. La richiesta dei dati è stata quasi sempre accolta e ha permesso di raggiungere notevoli risultati, in termini di copertura e completezza delle informazioni. In particolare, grazie alla disponibilità di Casalini Libri31, è stato possibile ottenere i dati bibliografici di oltre 1.500 articoli pubblicati su Accademie & biblioteche d’Italia32, AIDAinformazioni33 e Il bibliotecario: rivista di studi bibliografici34, che vengono indicizzate, grazie a specifici accordi con gli editori, sulla piattaforma Torrossa. Purtroppo, non è stato possibile ottenere i dati disaggregati degli articoli de La Bibliofilia e dei Nuovi annali della scuola speciale per archivisti e bibliotecari, perché, per «una scelta dell’editore e delle Direzioni delle riviste, non vengono resi disponibili su Torrossa i metadati a livello articolo» (e-mail di Luisa Gaggini, 20 gennaio 2021).
Inoltre, l’archivio dei numeri di Biblioteche oggi precedenti al 2008, i cui dati non sono disponibili tramite OAI-PMH, è stato fornito in formato XLSX da parte della redazione della rivista e ha permesso di ottenere i dati di circa 3.200 articoli, colmando una lacuna che sarebbe stata assolutamente significativa35.
La fase successiva al caricamento massivo dei dati è consistita nel controllo di qualità dei dati. I potenziali problemi noti erano due: gli errori dovuti a un’errata identificazione degli item di Wikidata in fase di riconciliazione dei dati con OR (per esempio, l’assegnazione di un articolo a un item che rappresenta un omonimo dell’autore reale) e l’esistenza di item descritti in modo molto scarno (per esempio, autori con le sole proprietà essenziali).
Per monitorare le riviste di interesse del progetto è stata assegnata alle riviste italiane di scienze dell’informazione e delle biblioteche una specifica proprietà che le metteva sulla focus list del GWMAB (P5008)36. Attraverso questa marcatura è stato possibile avviare controlli mirati sulle principali entità oggetto del caricamento: gli articoli e gli autori.
Secondo lo stile di lavoro in Wikidata, i problemi relativi ai dati sono stati descritti in un’apposita pagina del progetto37, sulla quale venivano segnalati i punti critici, si offriva una query per individuare ed estrarre gli item relativi a ciascun caso problematico e si aggiornava lo status di risoluzione. In Wikidata, la pagina di un progetto, oltre a fornire un quadro dei problemi e il progresso del lavoro, ha il vantaggio di permettere a chiunque di intervenire e correggere gli errori, a partire proprio dalla descrizione del problema e dalla query predisposta. Il problema non è necessariamente limitato alle persone che hanno avviato il progetto, ma è proposto all’intera comunità di Wikidata e può essere gestito e risolto da qualsiasi volontario interessato.
Per gli articoli, la bonifica dei dati ha riguardato gli aspetti più disparati, dalla sistemazione di valori erroneamente doppi per alcune proprietà (data di pubblicazione, pagine) fino a casi di duplicazione identificati grazie alla presenza del medesimo DOI su item diversi.
Anche per gli autori sono stati previsti sistemi di monitoraggio, tramite l’elaborazione di specifiche query38 per l’individuazione di autori descritti in maniera troppo povera (per esempio, privi del cognome e privi di qualsiasi identificatore esterno, come VIAF, SBN, ISNI, ORCID ecc.).
Il lavoro di revisione degli autori non è concluso ed è da considerarsi continuamente ‘in corso’ per diverse ragioni. In primo luogo, la natura automatizzata della procedura di creazione degli autori si è basata necessariamente su un numero davvero limitato di proprietà, unitamente a una descrizione molto stringata e generica («autore di …»). In secondo luogo, non essendo disponibile un’opera di consultazione39 contenente l’anagrafe onnicomprensiva degli autori, per gli item creati ex novo e privi di qualsiasi identificatore, le strategie di miglioramento della qualità devono necessariamente passare da azioni manuali sui singoli item. Infine, la grande mole di dati caricati rende oneroso il lavoro e molto lungo il processo.
Dall’avvio del progetto, nell’ottobre 2020, il gruppo di lavoro ha realizzato il caricamento su Wikidata di tutti gli articoli pubblicati nelle seguenti riviste nell’arco cronologico indicato tra parentesi:
Ciascun articolo risulta corredato dei metadati essenziali (titolo, data di pubblicazione, numero di volume e fascicolo, DOI ecc.) ed è collegato alla rivista sulla quale è stato pubblicato e ai propri autori. Solo per il 18% degli articoli inseriti sono state collegate anche le parole chiave, perché molte riviste non le attribuiscono e perché si è scelto di collegare la parola chiave solo se era già rappresentata da un item in Wikidata, come già detto42.
Le riviste totalmente o parzialmente indicizzate sono quindi 17, su un insieme di 25 testate inizialmente individuate43. A queste si aggiungono Bibelot, che viene indicizzata autonomamente da un gruppo di bibliotecari toscani e Bibliothecae.it, da sempre in carico al gruppo redazionale della rivista44.
Nel complesso, come risultato del progetto e degli inserimenti occasionali e non sistematici operati da altri utenti di Wikidata, sono stati indicizzati in Wikidata 9.74945 articoli, dei quali 8.382 sono articoli in senso stretto e 1.367 sono recensioni46, distribuiti per rivista come risulta da Figura 5.
Dalla Figura 5 emerge chiaramente l’importanza della rivista Biblioteche oggi, che è seguita per numero di articoli e recensioni dalla rivista Bollettino AIB e poi da La Bibliofilia, e a seguire da DigItalia, AIDAinformazioni, JLIS.it, AIB studi, Bibliothecae.it, Accademie e biblioteche d’Italia e le altre. Se si considerano il Bollettino AIB e AIB studi come un’unica rivista (dal momento che la seconda è prosecuzione della prima), si conferma l’importanza della rivista pubblicata dall’AIB. Il dato relativo a La Bibliofilia, che è stata fondata nel 1899, risulta decisamente più basso del reale dal momento che – come si è visto – il caricamento dei dati in Wikidata parte dal 1950 ma è anche lacunoso. È ragionevole pensare che sia proprio quest’ultima la rivista italiana di biblioteconomia che ha pubblicato il maggior numero di articoli.
Il numero degli autori per rivista rispecchia sostanzialmente la situazione degli articoli, con 5.123 autori per Biblioteche oggi, seguiti a molta distanza dai 1.861 autori del Bollettino AIB, gli 837 de La Bibliofilia (dato che presenta il limite che si è detto) e dalle altre a seguire49. Diversi sono i dati se si escludono dal conteggio gli autori di sole recensioni50, come si vede dal grafico di confronto (Figura 6).
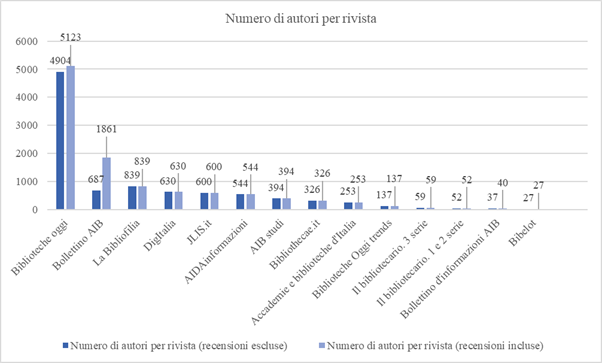
Figura 6 – Numero di autori per rivista
Un altro dato quantitativo che si può trarre dall’elaborazione consiste nell’individuazione degli autori con il numero più alto di articoli pubblicati sulle riviste italiane di biblioteconomia e inseriti in Wikidata (Figura 7) includendo51 o escludendo52 le recensioni. Si osserva, analogamente ai grafici precedenti, una lieve variazione dei dati in base al conteggio dei soli articoli o degli articoli e delle recensioni.
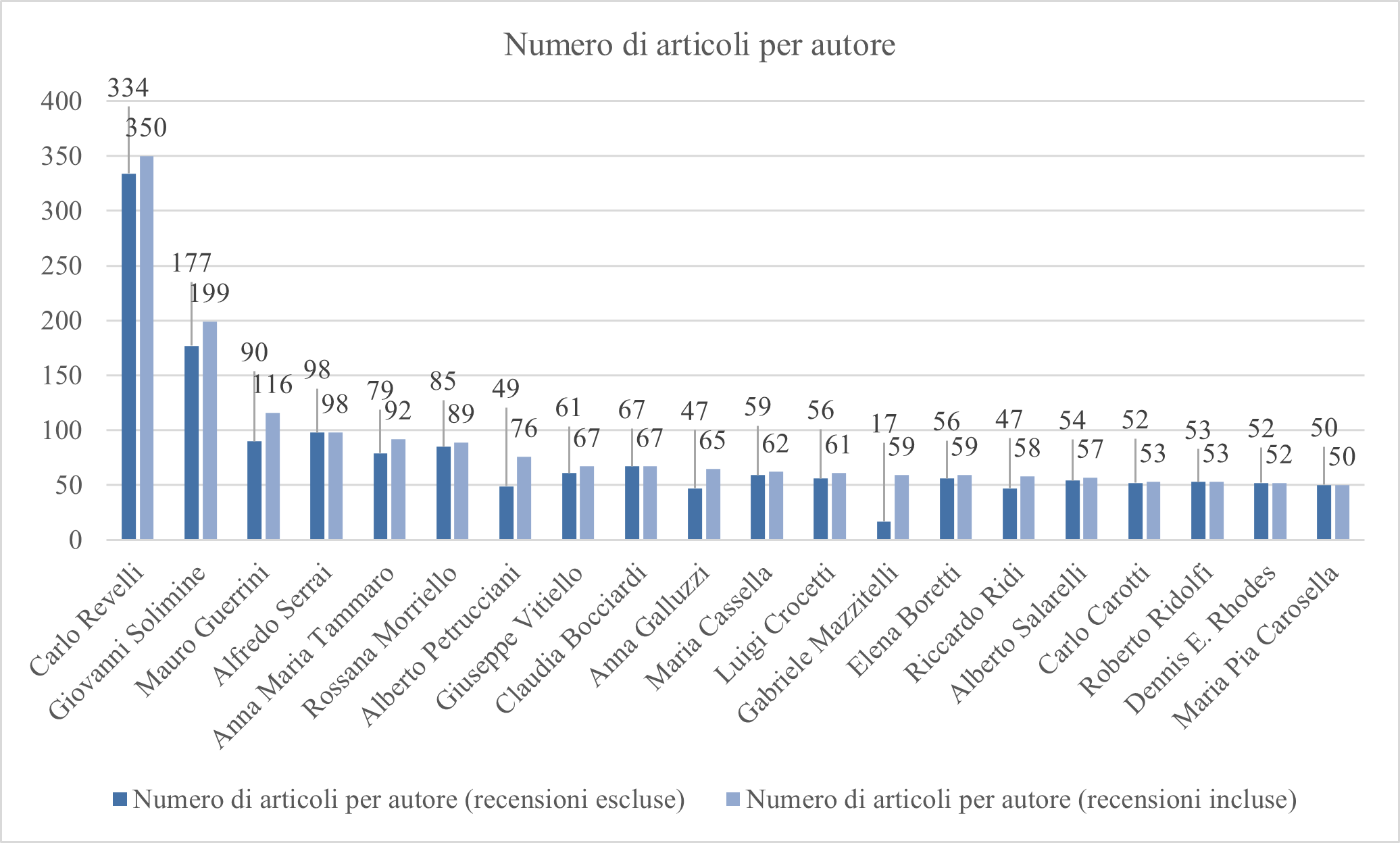
Figura 7 – Autori con almeno 50 articoli censiti in Wikidata (aprile 2023)
Anche in questo caso, i dati attualmente presenti risentono del caricamento parziale degli articoli della letteratura, oppure di progetti particolari dedicati all’inserimento della produzione totale di un autore specifico che possono in qualche modo falsare la panoramica complessiva delle pubblicazioni.
Questo è sicuramente il caso di Carlo Revelli, l’autore che risulta in assoluto il più prolifico, la cui produzione risulta più alta della media perché è stata oggetto di un editathon promosso dal GWMAB in sua memoria il 12 aprile 202153 e di uno specifico progetto di caricamento dei dati. L’alto numero degli articoli di Giovanni Solimine si spiega, almeno in parte, con la pluridecennale direzione e collaborazione con Biblioteche oggi, rivista sulla quale risultano pubblicati il 65% (132 su 203) degli articoli censiti54 e con la direzione decennale del Bollettino AIB.
In merito agli autori, sarebbe interessante compiere valutazioni quantitative anche di altra natura, quali l’occupazione, la distribuzione geografica, le fasce di età più ricorrenti o il loro sesso, le affiliazioni istituzionali. Per fare due esempi, si può osservare che, tra le 264 occupazioni degli autori che sono state censite, la prima e di gran lunga più diffusa è quella di bibliotecario (5.378), seguita da docente universitario (1.387), biblioteconomo (1.175), archivista (648), bibliografo (467), storico del libro (440) e paleografo (405)55; una mappa basata su 836 autori56 – cioè quelli per i quali è disponibile il dato del luogo di nascita – mostra che la distribuzione geografica è su base mondiale per gli autori nati prima del 1960, e che si riduce progressivamente all’Europa e all’Italia con la crescita dell’anno di nascita.
Analisi simili a queste consentirebbero di delineare un quadro preciso sugli autori delle riviste italiane di biblioteconomia, per esempio, sulle posizioni professionali e il contributo dell’accademia e della professione allo sviluppo della biblioteconomia in Italia, e anche di gettare luce diversa e nuova sulle riviste italiane e il loro posizionamento in Italia e in ambito internazionale.
Tuttavia, queste analisi allo stato attuale non sono ancora sostenute da una sufficiente quantità di dati (per esempio, il 48% degli autori non ha il dato dell’occupazione e l’84% non ha il dato del luogo di nascita). Possono essere indicative, ma non essere considerate affidabili. Inoltre, la quantità dei dati che caratterizza gli item degli autori è spesso molto diversa: si passa infatti da item di autori associati a identificativi internazionali e con informazioni di qualità a item provvisti del solo nome e cognome57. Un livello troppo difforme, dunque, per poter proporre delle valutazioni che diano conto delle ‘macro-caratteristiche’ degli autori biblioteconomici italiani.
Rispetto ai quesiti iniziali, la realizzazione del progetto ha mostrato che esistono metodi di caricamento degli articoli delle riviste più efficienti rispetto a quelli precedentemente utilizzati con Bibliothecae.it58 e con JLIS.it59, se l’obiettivo è quello di gestire grandi quantità di dati.
Le tecniche di controllo della qualità dei dati, sotto forma di query preimpostate e lanciate periodicamente per l’individuazione di item con descrizioni ‘critiche’ (per esempio, articoli privi di legame con l’autore, autori privi di identificatori largamente diffusi come VIAF, ISNI o SBN ecc.) si sono dimostrate efficaci per l’estrazione dei dati che richiedevano un miglioramento. Le query utilizzate per il controllo hanno dimostrato anche che la qualità dev’essere spesso raggiunta con interventi di gestione delle entità, che richiedono tipicamente un intervento umano qualificato e specializzato: questa parte del processo non può essere demandata alle macchine e dev’essere svolta da figure professionali come catalogatori o creatori di metadati.
A causa delle dimensioni del progetto, non è ancora stato completato il controllo di qualità sugli item degli autori; in prospettiva, comunque, non sarà possibile mai portare allo stesso livello qualitativo tutti gli item, per la natura stessa dei dati esterni a Wikidata. Per esempio, molte riviste sono spogliate in SBN, mentre alcune, come JLIS.it e Bibliothecae.it60, non lo sono; questo implica che non sono state create registrazioni di autorità, neppure minime, per gli autori di queste ultime due riviste. Quindi, se quegli autori avessero pubblicato in Italia solo in quelle riviste, non risulterebbero censiti in SBN e perciò non avrebbero un identificatore SBN da associare in Wikidata e i loro item rimarrebbero necessariamente di qualità semantica inferiore rispetto agli altri.
A causa dell’incompletezza della fase di descrizione degli articoli (soprattutto in relazione all’inserimento delle parole chiave) e degli autori, il progetto non ha potuto includere per il momento un’analisi dei dati citazionali con dettaglio e ampiezza maggiori di quella offerta nel paragrafo precedente (numero di articoli per rivista, numero di autori per rivista ecc.).
Infine, il progetto ha dimostrato che le analisi quantitative sugli articoli e sugli autori sono possibili e saranno significative e utili per gettare nuova luce sugli studi biblioteconomici italiani quando i dati caricati in Wikidata raggiugeranno una soglia adeguata.
Il progetto di caricamento dei dati si proponeva di creare e rendere disponibili i dati degli articoli pubblicati su ciascuna rivista da quando erano disponibili fino all’epoca del progetto stesso. Idealmente, da parte del gruppo di lavoro, sarebbero stati caricati i dati relativi agli articoli pubblicati fino al 31 dicembre 2021.
Questo obiettivo apriva il problema di stabilire se e come il progetto di valorizzazione si sarebbe potuto mantenere oltre quella data, in relazione a due nuclei principali di lavoro: il lavoro sugli articoli e quello sugli autori.
L’unica soluzione che sembrava percorribile, pur se con esiti incerti, era quella del coinvolgimento delle redazioni delle riviste di biblioteconomia; ognuna di esse avrebbe dovuto farsi carico dell’aggiornamento dei dati dal 2021 in poi: l’idea sembrava concretizzabile prima di tutto perché proprio in quel contesto era nata la prima esperienza di quel genere61.
Sono state quindi contattate le direzioni e le redazioni di AIB studi, Biblioteche oggi trends, Biblioteche oggi, Bibliothecae.it, JLIS.it e DigItalia, per presentare una proposta di collaborazione in questo senso: il nostro gruppo di lavoro avrebbe presentato il lavoro retrospettivo svolto e avrebbe dato la disponibilità a formare i collaboratori delle redazioni; queste poi si sarebbero assunte il compito di provvedere al caricamento sistematico delle pubblicazioni uscite a partire dal gennaio 2022 e all’arricchimento retrospettivo dei dati relativi alle pubblicazioni e ai loro autori.
Il corso, che aveva come contenuto l’estrazione dei set di metadati degli articoli tramite OJS, il trattamento con OpenRefine e il caricamento su Wikidata, si è svolto in tre giornate tra febbraio e marzo 2022, ed è stato suddiviso in un primo incontro introduttivo su Wikidata (dedicato a chi non aveva conoscenze su Wikidata), un secondo dedicato a illustrare le caratteristiche e il funzionamento di OAI-PMH e OpenRefine, con esempi di applicazione del GREL e un terzo incontro dedicato alla riconciliazione, alla creazione dello schema per Wikidata e al caricamento dei dati.
Il corso ha dato l’esito sperato per due redazioni: quella di AIB studi e quella di JLIS.it, che ora caricano autonomamente i dati di ogni nuovo fascicolo in uscita.
Riguardo al tema dell’arricchimento degli item degli autori, sono stati messi in atto due tentativi: il primo è stato coinvolgere la comunità dei bibliotecari italiani, contando sul fatto che molti di essi erano anche autori di pubblicazioni comparse sulle riviste censite. Questo approccio richiedeva di contattare gli autori e di metterli in condizione di fornire i dati anche nel caso – più probabile che no – in cui non fossero in grado di utilizzare Wikidata in modo autonomo. Si è pensato perciò di diffondere una richiesta di collaborazione tramite AIB-CUR, di predisporre una query che fornisse l’elenco degli autori sui quali c’erano informazioni scarse e un modulo Google attraverso il quale si potevano inviare le informazioni possedute. La mail è stata inviata il 15 gennaio 2022, ma l’esito è stato totalmente fallimentare, perché un solo bibliotecario ha fornito i dati per un solo item.
Inoltre, sempre riguardo all’arricchimento dei dati relativi agli autori, si è pensato che anche le redazioni delle riviste avrebbero potuto svolgere un ruolo di importanza fondamentale nel raccogliere dati autorevoli e di qualità direttamente dagli autori che sottomettono gli articoli da pubblicare. Nell’ambito del corso, si è cercato di sensibilizzare le persone coinvolte, ma questo approccio richiede la riorganizzazione del flusso di lavoro delle redazioni e l’inserimento di un passaggio di raccolta (e magari pubblicazione) di brevi profili biografici degli autori.
Tra gli obiettivi iniziali del progetto era prevista una terza fase relativa all’analisi citazionale e bibliometrica sulla letteratura biblioteconomica nazionale, grazie al caricamento in Wikidata delle citazioni presenti in ogni articolo. Questi dati avrebbero infatti consentito un’analisi approfondita delle relazioni tra le riviste e gli autori ma soprattutto di portare alla luce quella rete di connessioni di temi, di problemi, di approcci e il loro variare diacronico, tutti elementi che caratterizzano una disciplina e la sua professione.
Purtroppo, non è stato possibile procedere nemmeno all’analisi di un singolo caso per l’impossibilità di trattare le citazioni bibliografiche utilizzando strumenti e procedure automatici o semi-automatici. Le citazioni bibliografiche sono infatti gestite nella pratica consuetudinaria delle riviste come blocchi unitari di testo, inserite nel file PDF o HTML dell’articolo: quasi mai l’autore è vincolato a presentare la sua bibliografia in un formato strutturato (RIS, EndNote, RefWorks ecc.) e gli unici cenni in tal senso sono formulati dalle riviste come un invito62.
Alla luce di queste considerazioni, l’unica modalità di inserimento di tali citazioni bibliografiche in Wikidata rimane a oggi quella manuale, che ovviamente risulta inapplicabile a una mole di dati così elevata come quella gestita all’interno del progetto, con un dispendio di tempo ed energie considerevole e in maniera del tutto insostenibile per il futuro.
Una strada preferibile è certamente quella di sensibilizzare gli autori verso l’uso di reference manager software come Zotero o simili, e dunque vincolare l’elaborazione delle bibliografie a formati ben strutturati e potenzialmente elaborabili con processi automatici; tale strategia, d’altra parte, implicherebbe una presa di posizione netta, nonché un orientamento comune e condiviso da parte delle riviste del settore.
Altra soluzione, più impegnativa per il carico di lavoro che ne deriverebbe, potrebbe consistere nella creazione di tali bibliografie strutturate da parte delle stesse redazioni su ogni singolo articolo, prevedendo per esempio delle modalità condivise tra gruppi come quella offerta da Zotero63.
Seppur dunque in maniera incompleta rispetto alle intenzioni iniziali, il progetto ha portato a risultati sufficienti a impostare una prima valutazione, quantitativa e in parte qualitativa, della produzione scientifica biblioteconomica italiana, raggiungendo inoltre l’importante traguardo di sensibilizzare a questo proposito le redazioni di alcune tra le maggiori riviste del settore.
Tuttavia, per il completamento del progetto sarà necessario proseguire con diverse azioni:
A questi obiettivi primari si aggiunge infine il più ambizioso proposito di aver in qualche maniera ispirato iniziative analoghe che, travalicando i limiti del contesto bibliotecario, nascano e si diffondano anche in ambiti culturali affini quali musei e archivi, enti e progetti culturali di più ampio respiro.
Articolo proposto il 22 giugno 2023 e accettato il 19 luglio 2023.
CARLO BIANCHINI, Università di Pavia, Dipartimento di musicologia e beni culturali, Pavia, e-mail: carlo.bianchini@unipv.it.
ANDREA MARCHITELLI, EBSCO Information Services, Torino, e-mail: amarchitelli@ebsco.com.
ALESSANDRA MOI, Università degli studi di Milano-Bicocca, Milano, e-mail: alessandra.moi@unimib.it.
Ultima consultazione siti web: 19 luglio 2023.