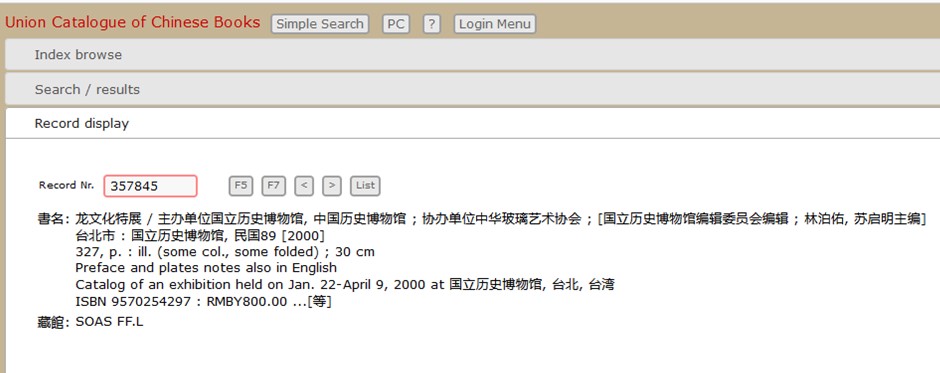
Figura 1 – Union Catalogue of Chinese Books. Visualizzazione di una descrizione in caratteri cinesi
Domenico Ciccarello
La globalizzazione sociale in atto e il ruolo dominante assunto da Internet hanno riportato in primo piano la concretezza dell’impegno necessario al servizio bibliotecario pubblico per mantenere fede alla sua tensione sommamente inclusiva, che si traduce nell’aspirazione di costituire la ‘porta di accesso locale alla conoscenza globale’. Sgombrando il campo da ogni ideale - oggettivamente inattuabile - di controllo bibliografico (e offerta) universale, l’ampiezza di orizzonti che i principi internazionali, a partire dal Public Library Manifesto fin dalle prime edizioni, attribuiscono alla biblioteca pubblica, va riferito non tanto al grado di esaustività di copertura della conoscenza prodotta (il contenuto), quanto alla garanzia dell’effettivo grado di empowerment dell’intera comunità servita (il target degli utenti da raggiungere): «I servizi della biblioteca pubblica sono erogati sulla base delle pari opportunità di accesso per tutti, indipendentemente dall’età, dall’etnia, dal genere, dalla religione, dalla nazionalità, dalla lingua, dallo status sociale e da qualsiasi altra caratteristica»1. Gli estensori del Manifesto sanno bene che il fattore linguistico immanente alle risorse bibliografiche richiederà, di norma, un input differenziale ai gestori delle biblioteche perché si ottenga l’equità di servizio auspicata: «Si devono fornire servizi e materiali specifici a quegli utenti, ad esempio le minoranze linguistiche […] che, per qualsiasi motivo, non possono utilizzare i servizi e i materiali ordinari»2. Rilevando quindi, in premessa, che la questione dell’informazione multilingue riguarda, per ovvii motivi che riguardano i suoi stessi presupposti, non solo le biblioteche pubbliche di base ma anche le biblioteche scolastiche, universitarie, specializzate, ecclesiastiche etc., proverò nei paragrafi che seguono a fare il punto su come stiano evolvendo i fattori abilitanti all’uso efficace delle risorse multi-alfabeto, mantenendo una distinzione d’ambito – per motivi che saranno chiariti nel corso del ragionamento – tra le raccolte fisiche descritte nei cataloghi di biblioteca e le collezioni ibride rese accessibili tramite discovery service o piattaforme/interfacce di biblioteche digitali.
Per iniziare il discorso, mi preme sottolineare come la questione della catalogazione multilingue dovrebbe trovare la sua collocazione più idonea nell’ambito della cosiddetta biblioteconomia critica, piuttosto che soltanto nella sfera delle tecniche catalografiche, che naturalmente vi sono implicate a pieno titolo. O perlomeno sarà questa la prospettiva entro cui, cercando di raccogliere alcuni degli spunti recentemente proposti da Rossana Morriello3, vorrei provare a riflettere sull’argomento. Se è vero che – per tornare alle dichiarazioni del Manifesto – «i servizi bibliotecari devono essere adattati alle diverse esigenze […] degli utenti multilingui»4, dovremmo anzitutto verificare in che misura, nel nostro Paese, tale adattamento ai bisogni delle comunità di madrelingua straniera sia stato finora realizzato. In anni ormai lontani, tale approccio squisitamente biblioteconomico è stato condotto ad ampio raggio dall’AIB, inizialmente in seno alla CNBP5, e poi con l’attività del Gruppo di studio Biblioteche multiculturali6, affrontandone sulla scorta delle linee guida internazionali le principali questioni politico-programmatiche. Non solo veniva approfondito il tema della catalogazione in alfabeti non latini, che pure è stato oggetto di un apposito seminario7, ma si individuava l'analisi di comunità come strumento utile a fare emergere meglio i bisogni dei nuovi arrivati8; si guardava alla cooperazione con le scuole, i primi istituti educativi ad essere stati investiti dall’‘ondata multietnica’9, e con gli enti del terzo settore; si studiavano e confrontavano diverse formule per la costruzione dello ‘scaffale multiculturale’ e la sua promozione verso gli utenti10; si osservavano le buone pratiche internazionali, con lo sguardo rivolto ai metodi più efficaci per offrire informazione di comunità multilingue, anche tramite le directory istituzionali di siti web (virtual reference desks)11. Le riflessioni prodotte dai bibliotecari che hanno partecipato a quelle elaborazioni12 convergevano su conclusioni pressoché unanimi, ribadendo a più riprese la necessità di superare prioritariamente due problemi (o se si vuole, due anomalie) della tradizione bibliotecaria italiana: il primo, quello di rimanere ancorata, adattandosi in modo forse troppo acritico e salvo poche eccezioni, a una prassi di descrizione e indicizzazione delle risorse in cui i titoli delle opere e ogni altro punto di accesso preferito ai documenti venivano definiti esclusivamente tramite la forma traslitterata delle voci di autorità (l’unica ammessa nell’indice SBN); il secondo, quello della mancanza di soluzioni innovative, di fronte ai limiti della normativa nazionale sull’assunzione nei ruoli del pubblico impiego, per consentire la presenza e il contributo operativo di staff madrelingua, multilingue e multiculturale, nelle nostre biblioteche13. Si tratta, come si può vedere, di un complesso di questioni interconnesse, di etica e di policy prima ancora che tecnologiche, riconducibili senz’altro a quelli che con terminologia più attuale oggi vengono chiamati ‘decolonialità’ o anche ‘principi DEI’14, e che senz’altro si ponevano già allora molto oltre un orizzonte puramente catalografico. Rimane la constatazione di una mancanza di fluidità nel percorso di sviluppo che, grazie ai progressi dell’automazione, avrebbe dovuto condurre in pochi anni le nostre biblioteche a una piena integrazione degli script non latini nei cataloghi elettronici, fattore che continua a incidere in modo fortemente negativo sulla qualità dell’informazione offerta dai nostri istituti15. Un nodo che, nonostante le dichiarazioni di intenti che accomunavano le istituzioni partecipanti al seminario di Venezia del 2003, non è stato ancora sciolto. In proposito, svilupperemo qui di seguito una serie di ulteriori osservazioni, anzitutto ripercorrendo nuovamente qualche passo indietro.
Il documento conclusivo del citato seminario “Babele e Alessandria”, scaturito dalle relazioni e dal confronto tra i partecipanti, e infine redatto da Chiara Rabitti per la CNBP dell’AIB, accanto alla questione centrale delle lingue e delle scritture del catalogo bibliografico (gestione delle registrazioni nei caratteri propri della lingua originale e uniformità dei sistemi di traslitterazione), richiamava l’attenzione anche sulla necessità di alcuni interventi di politica bibliotecaria necessariamente connessi all’obiettivo dell’equità di trattamento sul piano linguistico e culturale. Tali interventi, come concordavano i partecipanti, avrebbero dovuto essere indirizzati: 1) alla formazione di figure professionali competenti, in un blending mirato di competenze linguistico-culturali e tecnico-catalografiche; 2) all’adozione di un approccio di tipo cooperativo-consortile, basato sullo human resource sharing ovvero su programmi a sostegno della diffusione del know-how dei punti di eccellenza e della circolazione delle migliori pratiche; 3) alla creazione di gruppi di lavoro, coordinati a livello ministeriale, per l’individuazione delle soluzioni tecniche più idonee a migliorare le regole di catalogazione con riguardo ai sistemi di traslitterazione, come anche ad adeguare il sistema SBN secondo le esigenze degli utenti relative alla ricerca e al recupero delle risorse bibliografiche con l’impiego delle lingue e scritture non latine16.
La rielaborazione di uno dei contributi a quel convegno, presentata da Barbara Poli17 in questa rivista a qualche anno di distanza (2009), offriva ulteriori stimoli di non poco conto. In quel periodo, la recente adozione dello standard UNICODE nei principali sistemi gestionali di biblioteca aveva favorito una svolta sul piano tecnico, aprendo la strada a una decodifica più completa e uniforme dei caratteri non latini18. La bibliotecaria della Querini Stampalia aveva quindi sviluppato un’indagine sulla realtà statunitense, che già una quindicina di anni fa esibiva trasformazioni e realizzazioni di un certo impatto, ben fotografate dall’autrice. Tra queste, per il mondo OCLC, “Connexion” come sw di trattamento in back office dei dati bibliografici, che permetteva la creazione e la modifica di registrazioni del catalogo in dieci script diversi dal latino e dal greco (anche con l’opzione di potere ripetere uno stesso tag per più lingue-script), oltre ad offrire per i catalogatori l’accesso ad alcune authority list onomastiche19, e – per alcune lingue – ad uno strumento di conversione automatica dei dati bibliografici, dalle forme latinizzate a quelle nella scrittura originale, e viceversa, denominato “Transliteration tools”; inoltre i “Language sets” per aiutare biblioteche anche medio-piccole a costruire delle collezioni bibliografiche multilingue per le esigenze delle comunità locali; e “FirstSearch” come strumento di interrogazione del metaOPAC consortile con interfaccia utente in inglese, francese, spagnolo, arabo, cinese, giapponese e coreano.
Quanto agli orientamenti della Library of Congress, Poli annotava la scelta del merging delle registrazioni prodotte in diverse lingue/scritture originali (giapponese, cinese, coreano, arabo, persiano, ebraico e yiddish) all’interno di un database unico, “MDS-Books All”; evidenziava il recente impiego dei tag 4XX del MARC per registrare le voci d’autorità in caratteri non latini (non preferite), accanto al tradizionale trattamento mediante il tag 880 (alternate graphic representation), il che aveva portato al riversamento su NACO20 (e quindi alla piena disponibilità per i catalogatori) di circa mezzo milione di intestazioni nominali nella scrittura originale; non trattandosi, tuttavia, di forme pienamente controllate, il catalogo presentava abbondanza di duplicati.
L’autrice quindi menzionava alcuni interessanti programmi di catalogazione cooperativa in corso nel continente europeo: il “CJK Allegro”21, frutto degli sforzi congiunti di alcune biblioteche tedesche e inglesi; lo European Union Catalogue of Japanese Books22, curato da un gruppo di informatici di Tokyo; lo Union Catalogue of Chinese Books britannico (fig. 1)23;
Figura 1 – Union Catalogue of Chinese Books. Visualizzazione di una descrizione in caratteri cinesi
infine, per la Francia, la stratificazione del trattamento di lingue e scritture diverse in OPALE Plus della Bibliothèque Nationale, e le raccomandazioni espresse in un rapporto tecnico curato da Danièle Duclos-Faure per il Ministero dell’Educazione24, anche in vista dell’istituzione (avvenuta nel 2008) della Bibliothèque Universitaire des Langues et Civilisations. Poli concludeva auspicando nuovi passi in avanti anche per la situazione italiana, con l’occasione dell’implementazione delle nuove Regole di catalogazione (REICAT).
Il modello statunitense, basato sull’opzione di servizi specializzati “chiavi in mano”, che includevano sia la consulenza per la selezione e l’acquisizione di pacchetti di materiali bibliografici (utili, a seconda dei casi, per soddisfare le esigenze delle biblioteche pubbliche o di quelle universitarie e scolastiche), sia la gestione e acquisizione delle relative registrazioni bibliografiche, corredate delle pertinenti voci di autorità, ha trovato un corrispettivo molto simile nell’organizzazione bibliotecaria australiana. Con l’impiego del sw Aleph di Ex-Libris e l’implementazione di Unicode, lo staff di catalogatori multilingue della CAVAL Collaborative Solutions, partner della rete bibliotecaria pubblica di Victoria, coordinata dalla State Library of Victoria, ha garantito (per diversi anni, fino alla ristrutturazione dei servizi nazionali nel 2014) la gestione di un ambiente di catalogazione in grado di supportare la redazione di registrazioni bibliografiche in sessanta lingue differenti, nel rispetto delle scritture originali e con la possibilità di scambio bibliografico tra database diversi25. Senza dubbio, il successo del network australiano è stato dovuto alla compresenza di esperti linguistici, informatici, catalogatori nel quadro di un business model che fa del partenariato pubblico-privato una norma, anziché l’eccezione. Il team multidisciplinare ha affrontato da subito, tra gli altri, gli ostacoli dell’ordinamento delle voci d’autorità in un catalogo multilingue, delle problematiche di visualizzazione dei caratteri non latini, della corretta e uniforme resa dei diacritici.
Non si avvertirà mai abbastanza, in ogni caso, sull’estrema delicatezza delle questioni e sull’elevato grado di difficoltà e complicanze che caratterizzano la costruzione del catalogo multilingue e multi-alfabeto: non è una questione che si possa risolvere a buon mercato, con la sola ottimizzazione della decodifica dei caratteri. Ciascuna lingua e scrittura reca con sé specifiche modalità di impiego, particolarità redazionali, implicazioni culturali, i cui effetti arricchiscono l’universo catalografico (ma al tempo stesso, ne complicano non poco il processo descrittivo). Basti pensare, per limitarci ai caratteri di scrittura della lingua araba, al loro orientamento inverso (da destra a sinistra) rispetto a quelli latini, che impegna i sistemisti informatici all’impiego di appositi algoritmi volti a garantire la corretta direzionalità del testo sia in scrittura che in visualizzazione, caratteristica peraltro condivisa con altre lingue26. Oppure si consideri la profonda differenza, invalsa nei Paesi arabi nella costruzione dei nomi di persona, tra autori ‘moderni’ (dal Novecento in poi) e autori ‘classici’ (questi ultimi con forme del nome molto estese, che comprendono, oltre al nome proprio e al cognome – derivante da professione, casata o toponimi – anche appellativi spirituali, indicazioni nominali di paternità e di filiazione, dando luogo a molteplici varianti formali a seconda della fonte impiegata), a parte la necessità di qualificarli cronologicamente con una duplice trascrizione di data: calendario islamico e calendario gregoriano27.
Risulta, pertanto, comprensibile come l’accelerazione nelle attività di catalogazione delle collezioni in caratteri non latini sia stata accompagnata, in questi ultimi anni, da una moltiplicazione delle riflessioni in merito alle modalità di replica delle registrazioni delle medesime raccolte nella forma traslitterata, tema che suscita non poche preoccupazioni.
Sono questioni che, per un verso, riguardano le regole nazionali e i protocolli interni ai sistemi adottati, e non è un mistero che in Italia vi sia ancora una forte divergenza tra i due: mentre le nuove REICAT invitano il catalogatore all’equità di trattamento catalografico, ovvero «Informazioni che devono essere riportate o fornite in lingue che utilizzano sistemi di scrittura diversi dall’alfabeto latino si danno, per quanto possibile, sia nella scrittura originale sia in forma traslitterata o trascritta in alfabeto latino»28, nella Guida SBN, pur riconoscendo che per le aree 1, 2 e 4 le informazioni bibliografiche «vengono normalmente ricavate dalla risorsa e sono quindi nella lingua e/o scritture in cui esse appaiono», viene prescritto che «Testi in caratteri non latini si traslitterano»29 seguendo l’Appendice F del codice nazionale, e si esclude quindi, di fatto, il ricorso alla scrittura della lingua originale che compare nell’edizione descritta.
Per altro verso, le questioni e le relative riflessioni, spostandoci ora proprio sul versante della traslitterazione, si fanno ulteriormente complicate, dato che, come sappiamo, non vi è affatto soddisfazione, convergenza o accordo sufficiente tra catalogatori, specialisti dei domini linguistici e utenti comuni su quale standard (schema, tabella) sia opportuno adottare. Tale perdurante incertezza, insieme all’accumulo delle prassi difformi pregresse già abbondantemente sedimentatesi nei nostri cataloghi, ha condotto all’aumento delle varianti delle trasposizioni linguistiche, dei duplicati bibliografici ma soprattutto, e ciò che è più grave, moltiplica il rischio di perdita di ‘discoverability’ cioè inibisce in larga misura le chances di recupero delle risorse bibliografiche a seguito delle ricerche effettuate in catalogo.
Lo dimostrano gli innumerevoli problemi documentati, soprattutto nella rivista «Cataloging & classification quarterly», in merito alle prassi di traslitterazione relative a specifiche lingue/scritture latinizzate nei cataloghi occidentali: tra queste il cinese30, il coreano31, il persiano32, il giapponese33, l’arabo34, il russo35, a testimoniare come la strada da percorrere per la semplificazione dell’accesso alle raccolte multilingue sia ancora molto lunga. Nel contesto italiano, analogamente, sui numerosi (e ulteriori) aspetti e problemi specifici della catalogazione e traslitterazione in specifiche lingue e scritture sono intervenuti in momenti diversi, tra gli altri, Gabriele Mazzitelli (a proposito del cirillico, in questa rivista)36, Federica Olivotto (con riferimento al cinese)37, Chiara Camarda (con riguardo all’ebraico)38.
Sempre in ambito italiano, merita attenzione un ulteriore contributo molto recente al dibattito, in cui oltre a rilievi su aspetti particolari, vengono discusse alcune anomalie generali che caratterizzano la situazione italiana. Oscar Nalesini, dopo avere espresso, in premessa, le motivazioni di una preferenza per la catalogazione in lingua originale, ed evidenziato le componenti sociologiche sottese al trattamento bibliografico dei materiali in alfabeti diversi dal nostro: «[…] è bene tener presente che ogni scrittura, nonché ogni sua standardizzazione, ha anche connotazioni sociali, religiose, politiche, e di conseguenza il modo di codificare una scrittura in un’altra non è mai una scelta culturalmente neutrale»39, ha affrontato in dettaglio numerose questioni tecniche che si presentano di non facile soluzione con riferimento alle scelte di traslitterazione. La preferenza accordata dalle nuove REICAT agli standard ISO per un buon numero di lingue e/o scritture (tra cui greco, cirillico, arabo, ebraico, cinese), in diversi punti dell’appendice F del codice, non appare esente da contraddizioni; ulteriori difformità applicative, inoltre, vengono ordinariamente introdotte dalle consuetudini operative legate agli ambienti SBN e ai relativi protocolli e vincoli catalografici (insufficiente, ad esempio, il numero complessivo dei caratteri speciali fin qui gestiti dal sistema; imperfette le funzionalità della tastiera virtuale); infine, rimane il fatto che il livello di copertura linguistica delle tabelle di traslitterazione di ALA-LC risulta complessivamente più ampio di quello offerto dalle norme italiane. Ulteriori dubbi e perplessità operative, secondo Nalesini, legittimamente scaturiscono dall’impiego di una medesima scrittura per più lingue diverse, da problemi specifici che si presentano nell’uso dei segni diacritici, nonché dall’impossibilità pratica, dovuta in diversi casi alla natura degli alfabeti stessi, di stabilire corrispondenze biunivoche tra script originali e caratteri latini. Tutto ciò, a sua volta, di fatto impedirebbe di ottenere la ‘reversibilità’ del processo di traslitterazione (che invece sarebbe fortemente auspicabile, sia per motivi di uniformità, che per facilitare processi automatici di latinizzazione degli script nativi o, viceversa, di ‘retroconversione’ ovvero ripristino dei caratteri originari a partire dalla forma latinizzata).
In base a tali considerazioni, come ha suggerito Blair Kuntz, «For those opposed to transliteration, especially in an age where computerization has introduced Unicode in which native scripts can be displayed, entered, and searched in library catalogues, the practice is wholly unsatisfactory, serves no-one, and should probably be abolished»40. Lo stesso Kuntz, tuttavia, prosegue dimostrando che una qualche forma di traslitterazione, il più possibile affidabile e standardizzata, è di aiuto non solo al catalogatore, per facilitarlo nel controllo bibliografico delle collezioni e nella loro indicizzazione, ma anche agli utenti, in genere molto diversi tra loro quanto a provenienza, quanto a esigenze e motivazioni di ricerca, e infine quanto alla padronanza della lingua in cui sono redatti i documenti cercati. Forse, allora, come spesso accade, la verità sta nel mezzo, e cioè è necessario sapere sfruttare l’artificio della traslitterazione di titoli, autori e altri elementi descrittivi, ma ciò obiettivamente non appare sufficiente: «Why should a native speaker even bother searching for an item using transliteration, when searching using the original script is so much more reliable and efficient?»41. Dello stesso avviso James E. Agenbroad, secondo il quale la traslitterazione, in realtà, dovrebbe essere usata solo come punto di accesso aggiuntivo (per maggiore comodità dell’agenzia catalografica ed eventualmente degli utenti) rispetto all’unica modalità di accesso che andrebbe garantita sempre e comunque, quella della forma originale della descrizione e delle voci di autorità: «To provide equal and effective access, a library with a multiscript collection for readers of different scripts needs a multiscript catalog based on cataloguing rules that specify access in the original script. It may also need access via the script most used by most of its readers»42. E a proposito di equità, vorrei aggiungere nel paragrafo seguente qualche considerazione su uno dei molti paradossi del digitale.
Tra i servizi offerti dalle biblioteche in ambiente digitale, ormai da diversi anni hanno progressivamente preso piede, soprattutto nei contesti delle istituzioni accademiche e di ricerca, i discovery tool. Come sappiamo, si tratta di strumenti di ricerca integrata, ‘federata’ delle informazioni bibliografiche, in grado di facilitare e massimizzare a beneficio dell’utente finale l’information retrieval dei contenuti bibliografici indicizzati dalle biblioteche43. Il serbatoio informativo a cui attingono i discovery service è costituito da una knowledge base in continuo aggiornamento, che viene alimentata a) dai metadati delle risorse disponibili tramite il catalogo bibliografico, b) dai metadati relativi al flusso delle collezioni digitali in abbonamento attivo, e c) dai metadati della letteratura scientifica liberamente disponibili in modalità open access di cui sia stato dinamicamente effettuato un harvesting a cura del soggetto commerciale produttore, eventualmente con il concorso attivo dell’organizzazione interessata.
La compresenza, accanto alle registrazioni del catalogo, di contenuti digitali nativi che normalmente sono stati prodotti, metadatati e archiviati da soggetti esterni alla biblioteca e con sistemi informativi diversi, ha creato in molti casi, tuttavia, il paradosso di una disuguaglianza nelle opportunità di discoverability e di presentazione al pubblico delle risorse bibliografiche in caratteri non latini, e ciò vale non solo per i titoli e gli autori, ma anche per i soggetti espressi con il linguaggio naturale. Ci spiegheremo meglio con un esempio. Una ricerca a caso, volutamente effettuata con la parola chiave generica الإسلامية (= islamico/a) tramite un discovery service di Ateneo, tra i molti risultati restituisce quello mostrato come esempio nella fig. 2.

Figura 2 – Visualizzazione della descrizione relativa a un contenuto digitale in abbonamento, a seguito di query effettuata tramite discovery tool nello script originale
Viceversa, l’utente dell’OPAC del medesimo Ateneo (dando per assodato che quell’OPAC segua le norme nazionali e ne condivida i limiti) sarà costretto a cercare unicamente nella forma traslitterata ‘al-Islāmīyah’ perché possa recuperare dei documenti cartacei in lingua originale pertinenti all’area tematica di suo interesse, seppure a suo tempo tali documenti sono stati appositamente selezionati e acquisiti dal SBA nella lingua e nello script nativo, in accordo con i docenti delle discipline e/o gli esperti madrelingua coinvolti.
In altre parole, nel caso delle risorse in alfabeti non latini, le registrazioni del nostro catalogo basate sulla sola traslitterazione, per quanto dettagliate, accurate e dotate di collegamenti a strumenti di indicizzazione raffinatissimi, sconteranno sempre un gap linguistico che non appare in alcun modo fungibile. Si considerino, ad esempio, i punti di accesso per soggetto alla descrizione mostrata in precedenza (fig. 2). Se possiamo tutti concordare che l’indicizzazione per parole chiave proposta dal produttore commerciale della risorsa digitale è ridondante e qualitativamente inferiore, per precisione e capacità di richiamo, rispetto all’indicizzazione controllata tramite thesaurus che i catalogatori sarebbero capaci di offrire per la medesima registrazione bibliografica (ad esempio con il Nuovo Soggettario BNCF), allora bisognerà pure ammettere che la questione dello script nativo si pone in modo decisivo anche con riguardo all’effetto abilitante che offrono le chiavi di accesso di tipo semantico in lingua originale alle descrizioni in catalogo. Anche in questo caso, come hanno dimostrato Magda el-Sherbini e Sherab Chen in un ampio contributo sul tema, che comprendeva un’indagine di customer satisfaction sull’impiego delle LCSH per i testi in caratteri non latini, realizzata nel 2010 e rivolta sia a bibliotecari che a studenti / utenti finali, la dialettica traslitterazione vs. lingua nativa presenta rilevanti aspetti critici che, di fronte al 68% di preferenze per la ricerca semantica mediante lo script originale, gli autori riassumono così: «In general, the number of statements regarding the difficulties librarians and end users encountered when they searched non-Roman items by controlled English subject terms indicates a significant level of dissatisfaction with the current controlled English subject heading system»44.
Tornando al confronto tra i set di metadati degli OPAC e quelli dei discovery service, la disparità nelle opportunità di accesso alle informazioni sulle risorse bibliografiche disponibili in script diversi dal latino, che a lungo andare rischia di tradursi un vero e proprio digital divide (paradossalmente, a dispetto degli strumenti – entrambi elettronici – impiegati in fase di ricerca), appare trasversale a numerose biblioteche accademiche e di ricerca in Italia, e sarebbe molto opportuno lavorare in forma cooperativa per risolverla nel modo più efficace. Lungimirante quanto promettente, in proposito, appare l’esito, ancorché non definitivo, del progetto ‘DREAM’, condotto qualche anno fa da un team di bibliotecari della Sapienza Università di Roma45, con il coordinamento scientifico del sinologo Federico Masini, e avente come obiettivo dichiarato quello di «creare un catalogo partecipato con descrizioni in scritture non latine (cinese, arabo, cirillico, giapponese, coreano, ebraico, ecc.)»46, per migliorare l’impatto informativo in favore degli utenti madrelingua, o comunque esperti in lingue scritte in alfabeti diversi dal latino. Partendo dagli esiti di un’indagine interna, condotta nell’ambito del progetto stesso, che si è focalizzata sugli OPAC delle più cospicue collezioni delle biblioteche accademiche e di ricerca italiane, i membri del progetto hanno potuto evidenziare che nel nostro paese almeno mezzo milione di risorse documentarie prodotte in alfabeti non latini è stato descritto in forma traslitterata, e verosimilmente almeno un altro milione attende ancora di essere catalogato online. Tale constatazione ha spinto il team progettuale ad affermare, in termini a nostro parere assolutamente condivisibili, che «the extensive transliteration practice in cataloguing has as a direct consequence the underrepresentation of our library collections both at national and international level»47. Mossi da tali motivazioni, i membri di DREAM hanno deciso di lavorare alla creazione di un ambiente di lavoro open source, indipendente dai sistemi di gestione bibliografica (ILS) commerciali, in cui ospitare una massa critica di dati catalografici relativi alle collezioni in caratteri non latini provenienti da più biblioteche, con registrazioni redatte secondo le norme, e con l’impiego degli script originali mediante la codifica Unicode UTF-8. Coerentemente a tale scopo, è stato compiuto anche un certo investimento per provare a implementare alcune caratteristiche utili (es. la bidirezionalità delle informazioni nei campi, la gestione degli identificativi VIAF per le voci di autorità, secondo la logica dei linked data) in dialogo con il sistema gestionale impiegato da Sapienza, Sebina Next; e per i dati di autorità è stato progettato anche un apposito modulo di raccolta in formato OAI-PMH. Il repository di informazioni così ottenuto, alimentato mediante strumenti e algoritmi di ‘search and match’ tra il catalogo di Sapienza e alcuni grandi cataloghi collettivi di biblioteche straniere (es. il catalogo elettronico della BNF, il multiOPAC del sistema bibliotecario bavarese, berlinese e brandeburghese B3Kat, e il SUDOC francese), ha richiesto un notevole sforzo di adattamento e di raffinamento in quanto i dati importati – seppure standardizzati – pervenivano pur sempre a DREAM da fonti e con protocolli MARC diversi. Obiettivo finale, sottolineano le autrici e gli autori, non è di creare un sistema alternativo a SBN ma, al contrario, anticipare la disponibilità di dati bibliografici ‘puliti’ per renderli disponibili, oltre che nell’OPAC di Polo, anche in Indice SBN non appena saranno state risolte le note problematiche tecniche che attualmente inibiscono il multilinguismo del catalogo nazionale.
Un altro percorso di sviluppo molto interessante, articolato a partire da una visione del tutto simile, è in atto presso la rete delle biblioteche romane ecclesiastiche URBE48. Tralasciando le tappe dell’evoluzione dei sistemi catalografici in uso presso la rete, tutti costituiti in modo indipendente da SBN, l’aspetto che mi sembra più rilevante per gli scopi di questo contributo consiste nell’innovatività delle pratiche di condivisione dei dati bibliografici (soprattutto per quanto riguarda gli authority data), che ha conseguenze significative anche con riguardo al trattamento delle registrazioni negli alfabeti originali. Lo si può constatare partendo dal più recente approdo degli sviluppi cooperativi di URBE, costituito da Parsifal49. Come ha spiegato recentemente il Direttore del Consiglio Direttivo di URBE Fabio Tassone, la novità di questo sistema per l’accesso e lo scambio di dati bibliografici, con i servizi connessi, «è avere prodotto, a partire dalla ‘clusterizzazione’ delle entità agenti, un authority file condiviso da mettere a disposizione dei partecipanti al progetto», in una logica progettuale che «si regge sul presupposto dell’uso degli identificativi provenienti da fonti autorevoli (VIAF, Wikidata, ISNI, ecc.)», seguendo «una visione della cooperazione tra le biblioteche nel contesto delle nuove tecnologie (LOD, BIBFRAME, ecc.)», il tutto «conciliando nel miglior modo possibile le esigenze degli utenti e dei bibliotecari con i presupposti teorici biblioteconomici e bibliografici e questi con le caratteristiche tecniche degli strumenti del progetto»50.
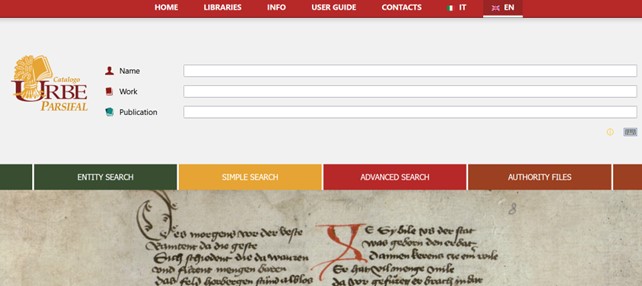
Figura 3 – Maschera di ricerca di PARSIFAL
In concreto, il metamotore Parsifal (fig. 3) offre l’opportunità di interrogare più OPAC di biblioteca, ognuno dei quali è gestito in proprio da una o più biblioteche aderenti, mettendo a valore il know-how dei catalogatori e le caratteristiche peculiari di ciascuna collezione (anche con riferimento alle lingue, scritture, culture che vi sono rappresentate), e di restituire in forma aggregata i risultati bibliografici esito delle ricerche degli utenti, grazie al pieno rispetto dei più recenti e aggiornati standard internazionali in ambito catalografico: RDA, LRM e BIBFRAME. Ne consegue che, nel display dei risultati della ricerca federata, si avrà il pieno rispetto degli alfabeti originali delle pubblicazioni, se così sono state catalogate nell’OPAC di provenienza (proprio l’esito che l’indice SBN al momento non permette di ottenere). Nel caso di Parsifal, il vantaggio di partenza è che diverse biblioteche della rete per anni avevano già condotto prassi operative positivamente improntate alla catalogazione di migliaia di risorse bibliografiche nello script originale51, come si può vedere dall’esempio random seguente, la copia dell’edizione in arabo del messaggio di Papa Giovanni Paolo II per la Giornata mondiale della pace 2001, posseduta da una delle biblioteche URBE52 e descritta come nella fig. 4.
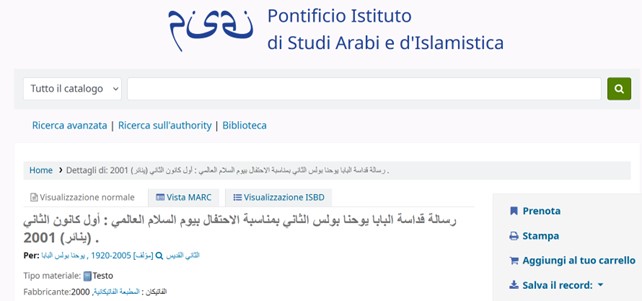
Figura 4 – Esempio di descrizione relativa a un documento in arabo posseduto dalla Biblioteca del PISAI
Inoltre, in Parsifal, l’impiego di identificatori persistenti per le entità del catalogo (autori, opere, pubblicazioni): a) permette il raggruppamento (clustering) di tutte le forme varianti ai fini del recupero corretto delle descrizioni bibliografiche collegate; b) fa funzionare correttamente l’applicazione dei linked open data (LOD) alle entità del catalogo (autori, opere, pubblicazioni); c) può facilitare l’import/export ‘pulito’ dei dati bibliografici da/verso altri formati (es. MARC21, MARC XML, etc.). Con riguardo all’aggregazione, nelle directory del catalogo, delle forme controllate anche per lingue e alfabeti diversi dal latino, esemplificazioni grafiche molto chiare vengono offerte nella Guida utente di PARSIFAL, a cui rimando per ulteriori approfondimenti sull’architettura dello strumento53.
Infine, si segnala che una strategia nuova per cercare di individuare strumenti di ausilio ai catalogatori, anche di quelli con una conoscenza non ottimale delle lingue e scritture diverse dal latino presenti nel portfolio di collezioni delle nostre biblioteche, è stata progettata ed è in corso di sperimentazione nel contesto degli studi religiosi, in particolare nell’ambito del progetto PNRR ITSERR, mirato a sostenere l’infrastruttura europea di ricerca RESILIENCE54. ITSERR è articolato in 12 sezioni (‘work packages’, WP), ognuna con un piano di lavoro e obiettivi specifici, accomunati dal tentativo di costruire strumenti di lavoro nuovi a supporto degli studiosi. Anche nel WP5, denominato “Digital Maktaba”55 e dedicato alla catalogazione multialfabeto, il tentativo è quello di sfruttare le nuove frontiere delle digital humanities a supporto degli studi religiosi e dell’attività delle biblioteche, mediante l’impiego di tecnologie di intelligenza artificiale (AI), big data (BD) e calcolo ad alte prestazioni (HCP). Nello specifico, le applicazioni sono rivolte in primo luogo a una cospicua raccolta digitale di documenti scientifici in lingua araba (monografie, periodici, altri materiali documentari in forma digitale, non tutti in forma ‘editabile’ tale da favorire il riconoscimento immediato dei caratteri), posseduta dalla Biblioteca “Giorgio La Pira” della Fondazione FSCIRE, con l’obiettivo di individuare il workflow più efficace, basato su software di Optical Character Recognition (OCR), strumenti di Natural Language Processing (NLP) e con algoritmi definiti dagli esperti informatici che fanno capo al progetto, per potere estrarre metadati dai documenti digitali e permettere, come obiettivo finale, ai catalogatori di disporre di strumenti di catalogazione semi-automatica dei materiali in script diversi dal latino, il tutto si spera con output il più possibile rispondenti ai modelli e agli standard bibliografici. I primi step di lavoro del WP5 sono stati presentati in diverse sedi alle comunità degli studiosi di scienze dell’informazione e di linguistica computazionale56. Un’ulteriore presentazione di Digital Maktaba, rivolta ai bibliotecari, si è tenuta molto recentemente, nell’ambito del convegno nazionale organizzato dal Gruppo di studio dell’AIB sull’inclusione sociale57.
Riprendendo, per concludere, il filo del ragionamento sull’equità di servizio e ricollegandoci ai nuovi scenari venutisi a creare con la svolta della ‘biblioteca ibrida’, andrà aggiunto, a onore del vero, che oggi alcune delle problematiche gestionali ritenute fino a pochi anni fa di ardua soluzione ci appaiono molto più a portata di mano. Un caso lampante è costituito dalle opportunità di acquisizione/distribuzione di quotidiani e magazines in lingue e alfabeti non latini per gli utenti delle nostre biblioteche. Molti ‘non-millennials’ come me ricorderanno, in proposito, una proposta di intermediazione commerciale, risalente a una ventina di anni fa (e che ritenevamo lungimirante e innovativa, in quel preciso momento), da parte di uno tra i più attenti editori italiani di biblioteconomia e scienze dell’informazione58. Bene, nel giro di pochissimi anni, l’avvento delle licenze per l’edicola digitale a disposizione delle biblioteche italiane ha stravolto del tutto (e in positivo) lo scenario precedente, tanto che, giusto per fare un esempio, il mio Ateneo, con un singolo abbonamento e senza porsi alcun problema linguistico ai fini della catalogazione, ormai da diversi anni è in grado di offrire direttamente, tramite la piattaforma MLOL, a tutti i suoi utenti accreditati l’intero pacchetto digitale Press Reader consistente in oltre settemila titoli di seriali in modalità streaming, tra i quali (selezionando con un solo clic la lingua) quasi 300 in lingua cinese e poco meno di un centinaio in lingua araba (fig. 5)59.
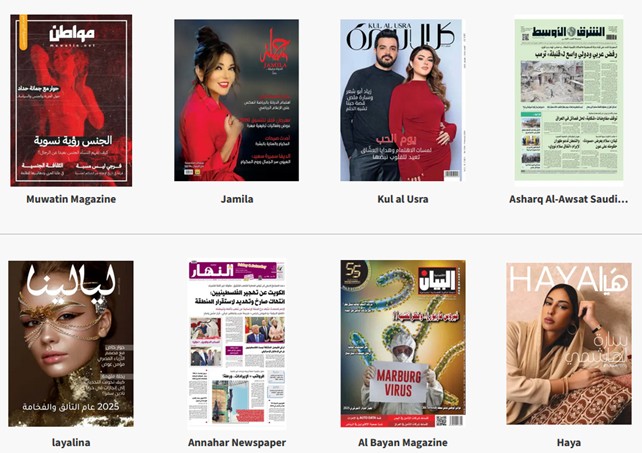
Figura 5 – Edicola digitale Unipa. Una selezione di magazines e quotidiani in lingua araba
Si potrebbe discutere a lungo, anche in questo caso, sulla condizione di disallineamento che si viene a creare tra accesso alla collezione digitale e accesso ai libri fisici tramite le descrizioni nel catalogo elettronico di Ateneo; fatto sta che il servizio c’è, funziona, vi si accede facilmente (nonostante i titoli vengano presentati nella piattaforma in forma traslitterata), e pertanto con una buona e costante attività di reference verso il target maggiormente interessato, l’edicola digitale può essere sempre meglio conosciuta e apprezzata.
Va aggiunto che, fortunatamente, per questa tipologia di materiale (e prevalentemente per i periodici di tipo scientifico), complessivamente il digital divide appare un po’ più circoscritto, al contrario le opportunità di ricerca dei periodici in alfabeti non latini nei nostri cataloghi si sono allargate considerevolmente. Tale affermazione, ancora prematura con riguardo all’ambiente di lavoro SBN (per il quale valgono le stesse limitazioni tecniche nella trasposizione dei dati catalografici già osservate per le monografie a stampa), risulta ormai pienamente valida con riferimento al repertorio preferito dalle biblioteche accademiche e di ricerca, e cioè il Catalogo italiano dei periodici ACNP, attualmente gestito dall’Area biblioteche e Servizi allo studio dell’Università di Bologna insieme alla Biblioteca centrale “Guglielmo Marconi” del CNR di Roma, con la partecipazione di un nutrito Comitato di biblioteche partecipanti, che con la loro quota di sottoscrizione contribuiscono a rendere finanziariamente sostenibile lo sviluppo dei servizi.
Nel giugno 2024, i gestori di ACNP hanno dato notizia dell’attivazione, nel sistema di gestione del database, di un nuovo campo denominato ‘titolo originale’, che può essere valorizzato anche con i caratteri non latini. Passata piuttosto in sordina nelle liste di discussione professionali, l’informazione appare invece estremamente rilevante nella prospettiva della catalogazione partecipata e del miglioramento del recupero dell’informazione, dal momento che apre a opportunità di immissione dati e di discoverability dei periodici in lingue e scritture diverse di cui, nel panorama catalografico italiano, non si riscontrano precedenti minimamente paragonabili.
Il funzionamento, sia per i catalogatori che per gli utenti finali, è molto semplice. In fase di descrizione, analogamente a quanto avviene con tutte le altre registrazioni dei seriali, la forma originale del titolo, qualora non sia già presente nel catalogo, può essere derivata dal registro ISSN collegato al gestionale ACNP, insieme con altri elementi della descrizione eventualmente presenti in lingua originale, come l’ente autore. L’attuale versione del Manuale ACNP60 ha già recepito le novità, segnalando le opportune prescrizioni nella sezione delle regole catalografiche61. Man mano che le biblioteche partecipanti ad ACNP proseguiranno la loro attività di popolamento delle notizie dei periodici in lingua originale nel database, queste saranno utilizzabili come chiave di accesso nella maschera di interrogazione dell’OPAC. Alternativamente, si può cercare il titolo con l’opzione, ugualmente disponibile, della forma traslitterata, che sarà sempre presente. Questo significa che già adesso l’interrogazione per titolo in ACNP consente di recuperare, ad esempio, una rivista irachena di lunga tradizione dedicata ai beni culturali, che in Italia risulta posseduta solo dalla Biblioteca dell’Accademia Nazionale dei Lincei e Corsiniana, sia ricercandola nella forma originale in arabo المورد (= La risorsa) che nella forma traslitterata ‘Al-Mawrid’, come nell’esempio mostrato nella fig. 6:
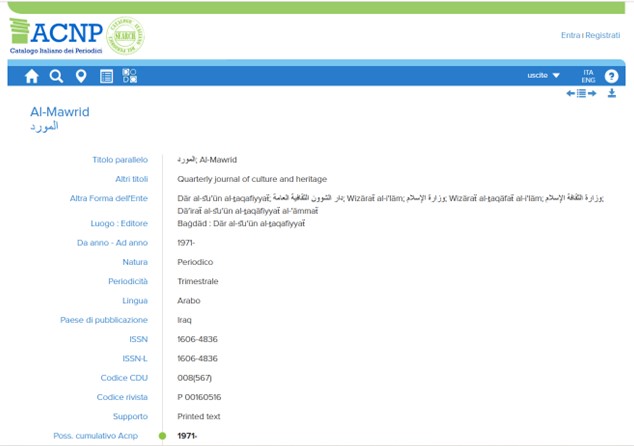
Figura 6 – OPAC di ACNP. Una risorsa in lingua araba visualizzata a seguito di ricerca tramite il titolo originale
L’immagine dell’OPAC di ACNP, in questo caso, mostra anche diverse forme varianti del nome dell’editore, che ne arricchiscono le potenzialità di recupero dei titoli collegati tramite la query nella scrittura nativa.
La sfida per la costruzione di una società multilingue e multiculturale basata su principi di parità di condizioni di accesso alla conoscenza registrata passa per la nostra capacità, come bibliotecari, di realizzare strumenti di mediazione linguistica efficaci e moderni62. Un catalogo elettronico in cui non siano stati messi a punto, sul piano delle soluzioni tecnologiche, i prerequisiti funzionali a garantire l’equità di discoverability delle risorse documentarie indipendentemente dalla lingua e dalla scrittura originale (un OPAC cioè che non permetta a ciascun utente di recuperare i documenti fisici della biblioteca nella loro forma linguistica nativa, ricercandoli in catalogo con i ‘query terms’ della medesima lingua e/o scrittura, come si fa ormai ordinariamente con le piattaforme editoriali delle collezioni digitali native), non risponde ancora pienamente alle aspettative degli utenti e rischia di inibire notevolmente, seppure senza alcuna intenzione da parte delle istituzioni che lo sviluppano, l’accesso a una parte selettiva della conoscenza registrata frutto del pensiero umano. Mentre si perfezionano le modalità idonee a garantire forme di accesso ‘artificiali’ ma pur sempre utili per vari aspetti delle attività di mediazione catalografica e informativa (le operazioni di traslitterazione), occorre lavorare di più e meglio per migliorare l’architettura degli strumenti di authority control, a tutti i livelli, ma soprattutto nei sistemi bibliografici nazionali che dovrebbero costituire l’architrave della struttura del servizio bibliotecario63. Il nuovo modello per l’architettura dei dati bibliografici BIBFRAME e lo standard RDA64, l’evoluzione delle mappature dei formati, degli standard di codifica dei caratteri e dei software di gestione informativa delle biblioteche, insieme allo sviluppo di più moderne, ricche e funzionali (per quanto apparentemente più complesse) architetture logiche dei database relazionali per il web (i linked open data, il web semantico)65 hanno prodotto una cassetta degli attrezzi profondamente rinnovata, formando un set di mattoncini e di sostanze adesive ‘reversibili’ con cui è possibile (se ne vedono ampie testimonianza all’orizzonte nella comunità LIS) costruire nuovi edifici bibliografici, forse più sostenibili, certamente più interoperabili rispetto al passato. E chissà che, un giorno neppure troppo lontano, l’oracolo non riesca pure a dare una mano d’aiuto all’architetto66.
Articolo proposto il 7 febbraio 2025 e accettato il 26 febbraio 2025.
DOMENICO CICCARELLO, Università degli studi di Palermo, Dipartimento di Culture e società, e-mail: domenico.ciccarello@unipa.it.
Ultima consultazione siti web: 20 dicembre 2024.
Questo lavoro è stato supportato dal progetto PNRR ‘Italian Strengthening of Esfri RI Resilience’ (ITSERR), finanziato dall’Unione Europea – NextGenerationEU (CUP: B53C22001770006), Principal Investigator: Fabrizio D’Avenia; Deputy Principal Investigator: Gianmarco Braghi. I punti di vista e le opinioni espresse sono esclusivamente dell’autore, e non riflettono necessariamente quelli dell’Unione Europea, che non può esserne in alcun modo considerata responsabile. L’autore, in qualità di RTD-A presso l’Università di Palermo, partecipa in particolare alle attività del Work Package 5, Digital Maktaba (WP Leader: Fabrizio D'Avenia; Product owners: Federico Ruozzi e Sonia Bergamaschi, Università di Modena e Reggio Emilia). Ai professori D’Avenia, Braghi, Ruozzi, Bergamaschi, e agli altri membri del WP5 (Sania Aftar, Domenico Beneventano, Amina El Ganadi, Luca Gagliardelli, Luca Sala, Giovani Sullutrone, Riccardo Vigliermo).
AIB studi, vol. 64 n. 3 (settembre/dicembre 2024). DOI 10.2426/aibstudi-14130. ISSN: 2280-9112, E-ISSN: 2239-6152 - Copyright (c) 2024 Domenico Ciccarello