Figura 1. L'esempio di componenti di uno statement RDF
di Iryna Solodovnik
«It's critical for Libraries to begin preparations
to become full participants in the world of Linked Data»1.
Il termine Semantic Web è stato coniato nel 2001 da Tim Berners-Lee2 per definire l'estensione del Web attuale, attribuendone la capacità di comprendere la semantica dei documenti digitali in rete e, in fase di ricerca, di interagire con l'utente nelle operazioni sofisticate di scoperta ed estrazione dei contenuti, nonché di elaborazione di nuovi set di risorse di conoscenza3.
L'idea del Web semantico nasce semplicemente dall'ampliamento dell'idea di utilizzare schemi di metadati (le informazioni relative ai dati, attraverso le quali è possibile ricavare informazioni sulla risorsa a cui sono associate) per descrivere domini di informazione, mappandone i dati rispetto a classi o concetti. «Un punto di forza principale del Web semantico è sempre stata l'espressione, sul Web, della grande quantità di informazioni del database relazionale formulate in una modalità processabile da una macchina. Il formato di serializzazione RDF [...] è un formato funzionale ad esprimere le informazioni di database relazionale»4. In questo modo si può disporre di strutture in grado di descrivere e automatizzare i collegamenti esistenti fra i dati, che nel Web semantico sono composti di tre livelli fondamentali. Al livello più basso abbiamo i dati, i metadati riportano questi dati ai concetti di uno schema, nello schema (spesso chiamato ontologia) si esprimono le relazioni fra concetti, che diventano classi di dati coinvolte nella strutturazione della conoscenza di una certa realtà (processi, domini di informazione)5. Il genere più tipico di ontologia per il Web è rappresentato da una tassonomia che definisce le classi di oggetti e le relazioni tra loro, e da una serie di regole di inferenza.
Le singole applicazioni del Web semantico possono operare processi di inferenza utilizzando specifici vocabolari definiti con i linguaggi formali e semi-formali comprensibili dai computer, interrogando così la semantica dei dati pubblicati sul Web.
In questo contesto, si aprono preziose opportunità per lo sviluppo e l'utilizzo di una nuova generazione di formati di metadati, di tecnologie per le biblioteche digitali e per la generazione di dati bibliografici di alta qualità sfruttando le tecnologie come Linked Data - «a recommended best practice for exposing, sharing, and connecting pieces of data, information, and knowledge on the Semantic Web using URIs and RDF»6 - atte a connettere i dati web tra di loro e con diversi schemi di dati di autorità pubblicati, arricchiti e validati sul Web in modo partecipato e condivisibile da diverse comunità di utenti. «Nell'universo bibliografico c'è un chiaro cambiamento di paradigma da formati record fissi alle ricombinabili dichiarazioni sui metadati. Le istituzioni e i sistemi bibliotecari che implementano archivi di dati bibliografici e relativi servizi dovranno necessariamente prevedere processi e strategie di fornitura dati compatibili con il framework Linked Data e di licenze adeguate»7.
Le tecnologie più rilevanti del Web semantico, definiti dal World Wide Web Consortium (W3C) sono:
1) XML (eXtensible Markup Language), una sintassi elementare per strutturare il contenuto dei documenti digitali. Attualmente, nelle tecnologie del Web semantico, XML non è una componente necessaria, considerando l'esistenza di una sintassi alternativa come Turtle (Terse RDF Triple Language), uno standard de facto per la serializzazione dei grafi RDF.
2) XML Schema, un linguaggio di descrizione del contenuto XML, il cui scopo è delineare quali elementi sono permessi, quali tipi di dati sono associati ad essi e quale relazione gerarchica hanno fra loro gli elementi contenuti in un file XML.
3) URIs (Uniform Resource Identifiers), indirizzi/identificatori univoci di risorse sul Web. URIs possono esprimersi tramite URN, DOI, URL accompagnati dal prefisso HTTP in modo che gli oggetti possano essere individuati da persone e da user agent sul Web.
4) RDF (Resource Description Framework), una sintassi formale di base per la codifica, lo scambio e il riutilizzo di metadati strutturati che possono descrivere la semantica di una risorsa, sia di quella reperibile sul Web (una pagina HTML, un documento XML o parte di esso), sia di quella che non si trova direttamente (un libro, un quadro). L'utilizzo di RDF per la descrizione semantica delle risorse offre, ovviamente, numerosi benefici in molti settori del Web: si potrebbero sviluppare diverse connessioni semantiche per aggregare i dati correlati, si potrebbero lanciare motori di ricerca più efficienti in grado di basare la ricerca non solo sulle occorrenze di parole contenute nei documenti ma anche in base alla caratterizzazione semantica dei documenti stessi, si potrebbero realizzare agenti software per il filtraggio dei contenuti di una risorsa in funzione di determinati criteri semantici impostati dall'utente.
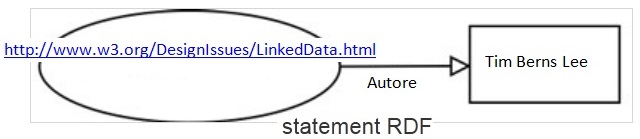
RDF si esprime attraverso due componenti: RDF Model and Syntax8 e RDF Schema (RDFS o RDF Vocabulary Description Language)9. Mentre la prima componente definisce il modello dei dati specificato attraverso la sintassi (RDF/XML, N3, Turtle, RDFa) per descrivere le risorse, la seconda permette di definire il significato e le caratteristiche delle proprietà e delle relazioni che esistono tra le risorse descritte dalla prima componente. RDF Data Model è basato su uno statement costituito da una tripla del tipo soggetto (una risorsa descritta mediante RDF), predicato (una proprietà, un attributo, una relazione definiti tra risorsa e valore tramite RDF Schema) e oggetto (un valore della proprietà) accompagnati, nella maggior parte di casi, da URIs che puntano ad altre risorse, consentendo cosi l'interoperabilità tra applicazioni che scambiano informazioni sul Web. La triplicazione automatica dei dati secondo l'articolazione soggetto-predicato-oggetto - ad esempio, la pagina http://www.w3.org/DesignIssues/LinkedData.html è scritta dall'autore Tim Berns Lee - è strettamente correlata al nostro modo di pensare e di costruire concetti (figura 1):
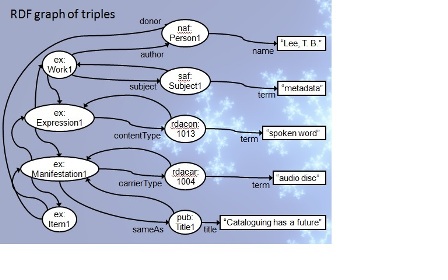
L'oggetto (Tim Berns Lee) dello statement rappresentato in figura 1, a sua volta, può essere un soggetto (risorsa) per aprire possibili percorsi di approfondimento sulla proprietà della risorsa. In questa prospettiva, dallo statement emerge un grafo RDF di conoscenza, rappresentato da un insieme di nodi interconnessi da URIs (ove è possibile) che identificano le loro proprietà (figura 2).
La tecnologia RDFS rappresenta un linguaggio ontologico semplice11, che consente di creare una sintassi per definire classi e proprietà per interpretare la semantica delle risorse. In un contesto RDF, le ontologie sono i vocabolari (definizioni di classi, istanze, proprietà) che catturano le strutture di dati di grafi RDF collegati. Nonostante l'esistenza di molti vocabolari RDF di dominio pubblico, che possono essere facilmente riutilizzati se coincidono con la semantica del dominio target, molti domini applicativi richiedono ontologie specifiche che possono riflettere meglio la semantica di dati e relazioni. Riconoscendo, però, i limiti di espressività di RDF e RDFS - in quanto RDF consente unicamente di indicare predicati binari (valore-attributo), e RDFS consente solo di stabilire gerarchie di classi e proprietà e di imporre vincoli per dominio e codominio - il W3C ha definito il Web Ontology Language (OWL).
5) Il linguaggio OWL12 permette di rappresentare esplicitamente il significato e la semantica di dati mediante vocabolari (ontologie) web formali. OWL esprime non solo proprietà (properties), classi (classes), istanze delle classi (individuals) e relazioni (di disgiunzione, di cardinalità, di uguaglianza) tra le classi, ma anche esporta tale conoscenza a diverse applicazioni, contribuendo maggiormente alla loro interoperabilità. L'espressività di OWL è costituita da tre sottolinguaggi: OWL Lite, OWL DL (Description Logic), OWL Full, ciascuno dei quali riproduce un'estensione del suo modello precursore più semplice (non viceversa). OWL Lite rappresenta un percorso di migrazione più rapida per thesauri e altre tassonomie gerarchiche e sistemi inferenziali, supportando, però, solo i valori di cardinalità a zero o uno, ed escludendo alcuni costrutti che esprimono relazioni tra classi (ad esempio disgiunzione, unione, istanziazione). OWL DL è abbastanza espressivo per trattare tutti i costrutti OWL, assegnando, però, solo alcuni vincoli sul loro uso (ad esempio una classe può essere sottoclasse di un'altra classe, ma non un'istanza di una classe; non si possono esprimere restrizioni di cardinalità per le proprietà transitive). OWL Full rende la massima espressività e la libertà sintattica dei costrutti RDFS, ma è difficilmente implementabile.
6) La tecnologia Simple Knowledge Organization System (SKOS)13, basata su RDF e RDFS, che supporta la rappresentazione e agevola la pubblicazione dei sistemi per l'organizzazione della conoscenza (KOS, Knowledge Organisation Systems) quali thesauri, schemi di classificazione, soggettari, schemi di intestazione per soggetto, e altri vocabolari controllati strutturati nel contesto del Web semantico.
7) SPARQL (Simple Protocol and RDF Query Language)14, un linguaggio di interrogazione dei grafi e sottografi RDF, il cui output sarà l'estrazione delle informazioni dalle basi di conoscenza distribuite sul Web.
Le tecnologie appena descritte rappresentano strati sovrapposti di linguaggi, ognuno dei quali usa o estende gli strati precedenti. Il collocamento di queste tecnologie può essere osservato nella figura 3.
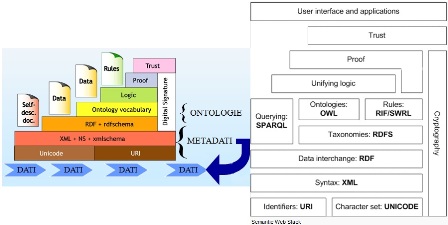
Fino al livello delle ontologie (metadati strutturati secondo un ordine logico e relazionati attraverso i concetti di un dominio di conoscenza) non vi è inferenza, ma solo rappresentazione della conoscenza. Sopra questo livello si colloca il livello logico che, tramite certi linguaggi (come SWRL, RuleML) e ragionamenti inferenziali automatici, estrae dalle asserzioni (statements) web una nuova conoscenza (machine understandable), che a sua volta sarà automaticamente integrata e riutilizzata dalle applicazioni. Inoltre, per raggiungere la piena potenzialità, le informazioni del Web semantico devono essere approvate (proof) e, di conseguenza, affidabili (trusted).
Uno dei problemi fondamentali del Web semantico è quello di rendere disponibili, integrabili e interoperabili le varie tipologie di dati sul Web. Tecnicamente, questo obiettivo può essere raggiunto attraverso opportune tecnologie capaci di operare la conversione da diversi formati di dati e database in RDF16, o di eseguire un markup RDF automatizzato dei siti (ad esempio attraverso le tecnologie POWDER, RDFa GRDDL, R2RML, RIF, Drupal7).
Tra i maggiori servizi che si prestano alla trasformazione dei dati strutturati in formati RDF/OWL possono essere elencati: Web services links & resources, SemWev, Beckett, SIMILE (RDF crosswalks), Semantic Bank, D2R Server (per l'esposizione di database relazionali in RDF). Infine, i sevizi di tagging semantico API Application Programming Interface: «un modo per i programmi di comunicare tra loro. Si può comprendere nei termini di come un programmatore invia istruzioni tra programmi diversi»)17 come, ad esempio, OpenCalais e Zemanta sono utili per trasformare blocchi di testi non strutturati in entità principali, topics, relazioni, e per eseguire l'estrazione di keywords, tagging automatico e la disambiguazione di entità e concetti, che possono fungere da output in RDF.
Al fine di sviluppare servizi e applicazioni web semanticamente interoperabili a livello globale, occorre lavorare non solo in direzione dell'armonizzazione di strutture, ma anche di apertura verso i formati dei dati18 e di uso di una terminologia precisa, specifica e condivisa (coinvolgendo attivamente i meccanismi dell'authority control 19che curano la qualità degli indici delle registrazioni) impiegando i dataset dei dati di autorità pubblicati in LOD Cloud, nonché le tecnologie SKOS20, sia per evitare ambiguità di significati dei metadati sia per contribuire all'arricchimento semantico dei loro valori. Questo, ovviamente, influirà in modo positivo anche in fase di definizione finale degli opportuni punti di accesso attraverso SPARQL Query Language.
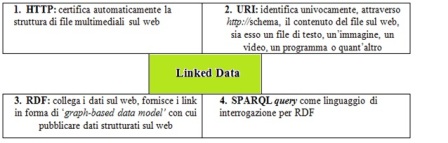
Il termine Linked Data (LD) è stato coniato da Tim Berners-Lee nel 200621 ed è considerato il primo passo verso il vero e proprio Web semantico. LD ha l'obiettivo di strutturare e di connettere i dati sul Web utilizzando URIs e RDF. In particolare, la tecnologia LD è formata dai già citati meccanismi del Web semantico come RDF Data Model , HTTP, URIs per costruire espliciti link RDF tra le entità correlate nel loro significato provenienti dai diversi dataset (di domini pubblico e privato)22 e SPARQL Query per interrogare i costrutti di LD (figura 4).
I dati provenienti sia dal dominio pubblico (dati aperti) che da quello privato (dati chiusi) possono essere ugualmente espressi come LD. In quanto al rapporto tra Linked Data, Open Data e Web semantico è interessante la definizione data da Paul Walk23:
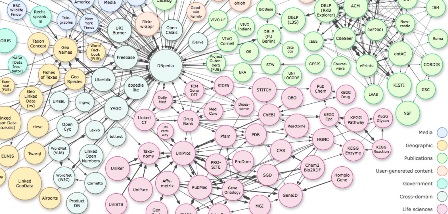
La crescente richiesta da parte degli utenti di servizi che consentono un elevato grado di interconnessione tra i dati provenienti da diverse fonti, ha portato allo sviluppo collaborativo e alla promozione di soluzioni pratiche per LOD in diversi settori, puntando ai fattori di maggiore interesse come l'interoperabilità semantica, la migliore fruibilità, l'ampio riutilizzo dei dati e la loro libera, aperta32 disponibilità per l'utente. L'importanza di LOD viene ampiamente riconosciuta anche per l'annotazione semantica33, per l'arricchimento dei dataset web attraverso modelli concettuali e authority data resi disponibili attraverso RDF34, per l'implementazione di high-level web-scale services per la ricerca.
In questa prospettiva e con il taglio tematico per i dati bibliografici, è interessante prendere visione delle iniziative di Archives & Museums (LODLAM) Group, IFLA'S Semantic Web Special Interest Group, Library Linked Data Group, dei progetti come Learning Linked Data, Linked Open Vocabularies, nonché delle relazioni di alcuni eventi recenti come Global Interoperability and Linked Data in Libraries, 2nd Linked Open Data Conference35, e altri ancora.
Nonostante il costante sviluppo di numerose guide pratiche, di una diversità di progetti e di un ricco framework tecnologico per la pubblicazione di LD, mancano ancora i meccanismi di automated reasoning su quest'ultimi. Inoltre, una delle critiche più comuni della visione del Web semantico è che gli standard come RDF, OWL e SPARQL sono difficili da comprendere concettualmente ed estremamente complessi da implementare.
Tuttavia, fino ad oggi la propagazione e l'implementazione di tecnologie Linked Data e Open Data allo scopo di mettere sul Web insiemi di dati aperti e connessi in modo interoperabile ha coinvolto diverse istituzioni, tra cui:
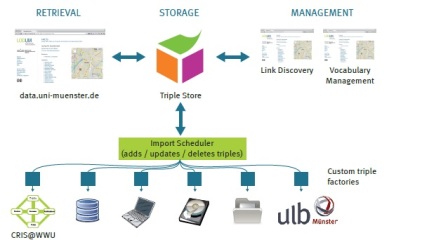

Tra i servizi web potenziati dai meccanismi di LD e SKOS segnaliamo:
Affinché il materiale dell'universo bibliografico diventi onnipresente nell'attuale contesto informativo dominato dal Web, è sempre più importante la sfida di rielaborare le rappresentazioni di dati bibliografici attraverso metodi innovativi e il lavoro collaborativo di diverse comunità che propongono nuove soluzioni di pubblicazione, integrazione, browsing e discovery dei contenuti informativi nel contesto globale del Web dei dati.
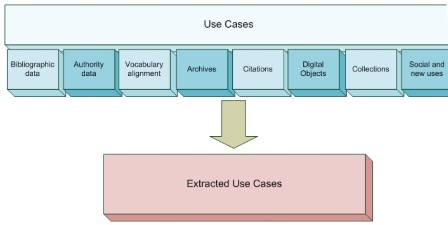
Seguendo i lavori del W3C, in particolare del progetto LOD della SWEO community, nel 2011 il gruppo di lavoro W3C Library Linked Data (LLDXG)61 - con lo scopo di sviluppare una standardizzazione condivisa del Web semantico all'interno della comunità bibliotecaria - ha pubblicato la relazione finale sui Library Linked Data (LLD), e i documenti di approfondimento come Datasets, Value Vocabularies, Metadata Element Sets proiettati su alcuni Use cases62 (figura 8).
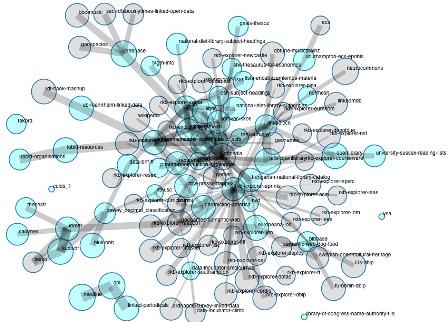
Nonostante gli indiscutibili vantaggi di LLD72, per i numerosi progetti che promuovono i metodi innovativi di gestione dei dati con le tecnologie del Web semantico sarà necessario un coordinamento specifico, accurato e deciso, al fine di contrastare il fenomeno dell'implementazione73 irregolare di tecnologie e principi LD (nei contesti di LOD e LLD) da parte di diverse comunità di utenti web.
Tra i principali ostacoli alla pubblicazione dei dati con i meccanismi LD vi è ancora la riluttanza, da parte di diverse comunità, nell'adottare nuove piattaforme software, così come la mancanza del personale con adeguate conoscenze e competenze per utilizzare queste piattaforme, prima e dopo la loro implementazione. Se i bibliotecari, esperti in catalogazione, nell'elaborazione e nella gestione di metadati si potrebbero sentire sopraffatti dalla prospettiva di produzione di metadati semantici e di ontologie, allora lo sarebbero ancora di più altre comunità operanti sul Web. Inoltre, ci sono tensioni tra open standards, open publishing richiesti per il Web semantico e i metodi esistenti per il supporto e il mantenimento delle infrastrutture di gestione dati. Da un punto di vista positivo, si potrebbe imitare le esperienze di alcune istituzioni (delle quali abbiamo dato un accenno nel paragrafo precedente) che hanno iniziato a pubblicare i loro dati bibliografici con tecnologie LD.
In quanto alle conclusioni del rapporto LLD, esse sono le seguenti:
Per contrastare le difficoltà di integrazione di dati bibliografici nel Web semantico, la relazione finale LLDXG ha fornito quattro principali raccomandazioni, con cui:
Il primo passo verso un Web che contenga dati bibliografici interpretabili nel loro significato anche dalle macchine è sicuramente quello di adottare un formato standard aperto come RDF, utilizzabile per raccogliere e categorizzare le informazioni sparse nel mondo della rete. RDF renderà disponibili i dati nella loro forma più pura (raw data78, dati puri senza formati e formattazioni), che consentirà di strutturarli e connetterli attraverso la tecnologia Linked Data in modo omogeneo entro lo spazio del Web of data. «Upcoming challenges will involve the strategic and technical alignment of catalogues and legacy systems in libraries and the authoring environments for scholarly communication - both in a data and service infrastructure based on the principles of the Semantic Web»79.
Un investimento finanziario e in know-how degli esperti di diversi settori che possano accrescere la qualità di architetture e tecnologie semantiche di LD, genererà di sicuro un ritorno positivo a medio e lungo termine nell'armonizzazione di diversi formati di Web-based data (provenienti da vari database relazionali), nel loro riutilizzo da parte diversi sistemi informativi e comunità web e nella creazione di un nuovo e potente strumento di ricerca e reperimento di informazioni attraverso le query mirate.
La sfida per i gestori dell'universo bibliografico, quindi, è quella di approfondire la conoscenza su LD, conoscere tutti i suoi vantaggi, leggere con sguardo laico i suoi strumenti, e promuovere la conoscenza e il consapevole utilizzo di Library Linked Data, tema che «non può non interessare la comunità bibliotecaria nel suo complesso»80, il che significa che ci saranno motivi maggiormente utili a far crescere il livello di riutilizzo e di interoperabilità dei dati, secondo la ormai famosa scala delle stelline promossa da Sir Tim Berners-Lee81.
Ultima consultazione siti web: 12 novembre 2012.
[1] Gillian Byrne - Lisa Goddard, The Strongest Link: Libraries and Linked Data, «D-Lib Magazine», 16 (2010), n. 11-12, http://dlib.org/dlib/november10/byrne/11byrne.html
[2] Tim Berners-Lee - James Hendler - Ora Lassila, The Semantic Web, «Scientific American Magazine», May 2001, http://www.scientificamerican.com/article.cfm?id=the-semantic-web
[3] Zareen Syed - Tim Finin, Creating and Exploiting a Hybrid Knowledge Base for Linked Data, in: Agents and Artificial Intelligence, Joaquim Filipe, Ana Fred, Bernadette Sharp (eds.) «Revised Selected Papers Series: Communications in Computer and Information Science», Springer, 129 (2011), p. 3-24, http://ebiquity.umbc.edu/paper/html/id/535
[4] Mauro Guerrini - Tiziana Possemato, Linked data: un nuovo alfabeto del web semantico, «Biblioteche oggi», 30 (2012), n. 3, p. 10, http://www.bibliotecheoggi.it/content/201200300701.pdf
[5] Claudio Gnoli - Carlo Scognamiglio, Ontologia e organizzazione della conoscenza, Lecce: Pensa Multimedia, 2008. V. anche il volume monografico Le ontologie, a cura di Maria Teresa Biagetti, «AIDA Informazioni», 28 (2010), n. 1-2, http://www.aidainformazioni.it/2010/122010.html
[6] Linked Data, Connect Distributed data across the web (the site of the Linked Data community), http://linkeddata.org/
[7] Antonella De Robbio, Forme e gradi di apertura dei dati. I nuovi alfabeti dell'Open Biblio tra scienza e società, «Biblioteche oggi», 30 (2012), n. 6, pp. 16-17, http://www.bibliotecheoggi.it/content/201200601101.pdf
[8] World Wide Web Consortium (W3C), RDF/XML Syntax Specification (revised) http://www.w3.org/tr/REC-rdf-syntax/
[9] World Wide Web Consortium (W3C), RDF Vocabulary Description Language 1.0: RDF Schema, http://www.w3.org/tr/rdf-schema/
[10] Gordon Dunsire, Linked Data, Libraries and the Semantic Web, in: Library science talk, 12-13 March 2012, http://www.nb.admin.ch/aktuelles/ausstellungen_und_veranstaltungen/00726/01611/03953/03958/index.html?lang=en
[11] Per approfondire vedere il Manuale per l'interazione con gli utenti del Web culturale, a cura di Pierluigi Feliciati e Maria Teresa Natale, 2009, http://www.minervaeurope.org/publications/handbookwebusers_it/chapter4_5.html
[12] World Wide Web Consortium (W3C), OWL Web Ontology Language. Overview, http://www.w3.org/TR/owl-features/
[13] World Wide Web Consortium (W3C), SKOS Simple Knowledge Organization System Primer, http://www.w3.org/TR/skos-primer; SKOS Use Cases and Requirements, http://www.w3.org/TR/2009/NOTE-skos-ucr-20090818/
[14] World Wide Web Consortium (W3C), SPARQL Query Language for RDF, http://www.w3.org/TR/rdf-sparql-query/
[15] Semantic Web Architecture, http://obitko.com/tutorials/ontologies-semantic-web/semantic-web-architecture.html; Semantic Web, http://en.wikipedia.org/wiki/Semantic_Web
[16] W3C RDB2RDF Incubator Group, A survey of current approaches for mapping of relational databases to RDF, 2009, http://www.w3.org/2005/Incubator/rdb2rdf/RDB2RDF_SurveyReport.pdf
[17] Open Knowledge Foundation, Open Data Handbook. Glossario, http://opendatahandbook.org/it/glossary.html#term-application-programming-interface
[18] Antonella De Robbio, Forme e gradi di apertura dei dati. I nuovi alfabeti dell'Open Biblio tra scienza e società cit.
[19] Authority control. Definizioni ed esperienze internazionali. Atti del convegno internazionale, Firenze, 10-12 febbraio 2003, a cura di Mauro Guerrini e Barbara, Tillet, con la collaborazione di Lucia Sardo. Firenze University Press, Associazione italiana biblioteche, 2003, http://www.fupress.com/Archivio/pdf/4383.pdf
[20] World Wide Web Consortium (W3C), SKOS Simple Knowledge Organization System, http://www.w3.org/2004/02/skos/
[21] Lisa Goddard - Gillian Byrne, Linked data tools: semantic web for the masses, «First Monday», 15 (2010), n. 11, http://www.uic.edu/htbin/cgiwrap/bin/ojs/index.php/fm/article/view/3120/2633
[22] «While, to date, it is the case that Linked Data has been demonstrated using public Web data and many desire to expose more through the Open Data movement, there is nothing preventing private, proprietary or subscription data from being Linked Data», in: AI3 (Adaptive Information Innovation Infrastructure), What is Linked Data?, http://www.mkbergman.com/447/what-is-linked-data/
[23] Paul Walk's weblog, Linked, open, semantic?, 2009, http://blog.paulwalk.net/2009/11/11/linked-open-semantic/
[24] Tom Heath - Christian Bizer, Linked Data: evolving the web into a global data space, «Synthesis lectures on the semantic web: theory and technology», Morgan & Claypool, 2011, http://linkeddatabook.com/editions/1.0/
[25] Mauro Guerrini - Tiziana Possemato, Linked data: un nuovo alfabeto del web semantico cit., p. 7.
[26] Richard Cyganiak [et al.], Semantic Sitemaps: Efficient and Flexible Access to Datasets on the Semantic Web, in: Proceedings of the 5th European Semantic Web Conference, ESWC, 2008, http://richard.cyganiak.de/2008/papers/sitemaps-eswc2008.pdf
[27] Dublin Core. Building blocks for interoperability, Designing Interoperable Metadata on Linked Data Principles, 2009, http://dublincore.org/resources/training/NISO_Webinar_20100825/dcmi-webinar-03.pdf
[28] Richard Cyganiak - Anja Jentzsch, Linking Open Data Cloud Diagram, http://richard.cyganiak.de/2007/10/lod
[29] Europeana ha pubblicato un video per spiegare cosa sono i LOD e perché apportano benefici sia agli utenti che ai fornitori di dati: Linked Open Data. What is it?, http://vimeo.com/36752317
[30] World Wide Web Consortium (W3C), SweoIG/TaskForces/CommunityProjects/LinkingOpenData, http://www.w3.org/wiki/SweoIG/TaskForces/CommunityProjects/LinkingOpenData
[31] Evan Sandhaus - Rob Larson, First 5000 tags released to the Linked Data Cloud, «New York Times», 29 ottobre 2009, < http://open.blogs.nytimes.com/2009/10/29/first-5000-tags-released-to-the-linked-data-cloud/
[32] Antonella De Robbio, Forme e gradi di apertura dei dati. I nuovi alfabeti dell'Open Biblio tra scienza e società cit. A supporto di LOD vedi anche Foundation Conference of European National Librarians, Europe's national librarians support Open Data licensing, 2011, http://app.e2ma.net/app2/campaigns/archived/1403149/f14691f55d5483aff43360a9b4aa7d35/; Harvard Library, Open Metadata, 2012, http://openmetadata.lib.harvard.edu/
[33] Delia Rusu - Blaž Fortuna - Dunja Mladeniæ, Automatically Annotating Text with Linked Open Data, in: WWW2011 workshop: Linked Data on the Web (LDOW2011), Hyderabad (India), 2011, http://events.linkeddata.org/ldow2011/papers/ldow2011-paper09-rusu.pdf
[34] Gordon Dunsire, Interoperability and semantics in RDF representations of FRBR, FRAD and FRSAD, 2010, http://www.gordondunsire.com/pubs/pres/InteropSemanticsRDFFRBR.ppt; World Wide Web Consortium (W3C), Use Case Authority Data Enrichment, http://www.w3.org/2005/Incubator/lld/wiki/Use_Case_Authority_Data_Enrichment
[35] LODLAM, Linked Open Data in Libraries, Archives, and Museums, http://lodlam.net/;IFLA, Semantic Web Special Interest Group, http://www.ifla.org/swsig; World Wide Web Consortium (W3C), W3C Library Linked Data Incubator Group, http://www.w3.org/2005/Incubator/lld/; Learning Linked Data project, http://lld.ischool.uw.edu/wp/About/; Linked Open Vocabularies, http://lov.okfn.org/dataset/lov/index.html. Presentazioni del seminario internazionale Global Interoperability and Linked Data in Libraries, Firenze, June 2012, «Jlis.it», 3 (2012), http://leo.cilea.it/index.php/jlis/issue/view/368/showToc; 2nd Linked Open Data Conference from the Cataloguing and Indexing Group in Scotland (CIGS). Opening Library Linked Data to National Heritage: Perspectives on International Practice, September 2012, http://aims.fao.org/events/2nd-linked-open-data-conference-cataloguing-and-indexing-group-scotland-cigs-opening-library-.
[36] Digital Curation Centre, Cite Datasets and Link to Publications, http://www.dcc.ac.uk/resources/how-guides/cite-datasets
[37] AIMS, LODE-BD Recommendations 2.0 available on AIMS now!, http://aims.fao.org/community/blogs/lode-bd-recommendations-20-available-aims-now
[38] Carsten Keßler - Tomi Kauppinen, Linked Open Data University of Münster. Infrastructure and Applications, http://kauppinen.net/tomi/lodum-eswc-2012.pdf
[39] Library of Congress, Library of Congress Authorities, <http://authorities.loc.gov/>; LC Linked Data Service Authorities and Vocabularies, http://id.loc.gov/
[40] Library of Congress, A Bibliographic Framework for the Digital Age (October 31, 2011), http://www.loc.gov/marc/transition/news/framework-103111.html
[41] Open bibliography and Open Bibliographic Data, German National Library goes LOD & publishes National Bibliography, http://openbiblio.net/2012/01/26/german-national-library-goes-lod-publishes-national-bibliography/
[42] Attualmente ci sono più di 1.6 milioni di record bibliografici con l'identificatore per titoli seriali ZDB-ID che, a differenza di ISSN, distingue le versioni a stampa da quelle elettroniche, http://dispatch.opac.d-nb.de/DB=1.1/
[43] Mirjam Keßler, Linked Open Data of the German National Library, in: ECO4r Workshop LOD of DNB, Berlin: Deutsche National Bibliotek, 2010, http://www.eco4r.org/workshop2010/eco4r_workshop2010_mirjam_kessler.pdf
[44] Secondo l'Open definition. V. Open Knowledge Foundation Italia, http://it.okfn.org/; CC0 1.0 Universal (CC0 1.0), http://creativecommons.org/publicdomain/zero/1.0/
[45] ISKO UK, Hungarian National Library OPAC and Digital Library Published as Linked Data, 2010, http://iskouk.blogspot.com/2010/05/hungarian-national-library-opac-and.html
[46] Neil Wilson, Linked Data Prototyping at the British Library, 2010, http://talis-linkeddata-libraries.s3.amazonaws.com/Linked%20Data%20Prototyping.pdf; British National Bibliography (BNB), Linked Open Data, http://thedatahub.org/dataset/bluk-bnb
[47] Bibliothèque nationale de France, http://data.bnf.fr/; Data.bnf.fr: an overall presentation, http://data.bnf.fr/docs/databnf-presentation-en.pdf
[48] Biblioteca Nacional de España, Datos enlazados en la BNE, http://www.bne.es/es/Inicio/Perfiles/Bibliotecarios/DatosEnlazados/index.html
[49] MARiMbA, http://mayor2.dia.fi.upm.es/oeg-upm/index.php/en/downloads/228-marimba
[50] Circa 2,5 milioni di record bibliografici (monografie antiche e moderne, registrazioni sonore) e 4 milioni di authority record sono stati trasformati in RDF. Il processo di trasformazione ha generato circa 58 milioni di terne RDF e 600 collegamenti (owl:sameAs) ad altri set di dati come DBpedia o VIAF, http://thedatahub.org/dataset/datos-bne-es
[51]lobid.org, http://lobid.org/about
[52] OCLC, OCLC provides downloadable linked data file for the 1 million most widely held works in WorldCat, http://www.oclc.org/us/en/news/releases/2012/201252.htm. I contenuti in un unico file LD sono scaricabili da: http://purl.oclc.org/dataset/WorldCat/datadumps/WorldCatMostHighlyHeld-2012-05-15.nt.gz
[53 ]Europeana Libraries, Aggregating digital content from Europe's libraries. D5.1. Report on the alignment of library metadata with the European Data Model (EDM), http://www.europeana-libraries.eu/documents/868553/1eade085-34ac-487f-82af-d5cd2545e619; Bibliographic Data, <http://thedatahub.org/group/bibliographic
[54] Martin Doerr [et al.], The Europeana Data Model (EDM), in: World Library and Information Congress: 76th IFLA General Conference and Assembly. Open access to knowledge - promoting sustainable progress, Gothenburg (Sweden), 2010, Meeting 149, Information Technology, Cataloguing, Classification and Indexing with Knowledge Management, http://conference.ifla.org/past/ifla76/149-doerr-en.pdf
[55] «Libraries, museums, newspapers, government portals, enterprises, social networking applications, and other communities that manage large collections of books, historical artifacts, news reports, business glossaries, blog entries, and other items can now use Simple Knowledge Organization System (SKOS) to leverage the power of linked data», in: World Wide Web Consortium (W3C), SKOS Simple Knowledge Organization System, cit.
[56] Europeana Linked Open Data (LOD), http://pro.europeana.eu/linked-open-data. Europeana LOD Pilot datasets comprende circa 2,5 milioni di record (Europeana conta più di 21 milioni record) sotto la licenza CC0.
[57] Europeana, Business Plan 2012, http://pro.europeana.eu/documents/858566/c0c6e31f-5174-4898-9771-f9b9a8d1d4d7
[58] AGROVOC, http://aims.fao.org/standards/agrovoc/about
[59] Marta Motta - Dario Rodighiero, Il Thesaurus del Nuovo soggettario interpreta SKOS, 2010, http://www.iasummit.it/2010/papers/motta-rodighiero.pdf
[60] EARTh, http://uta.iia.cnr.it/earth.htm
[61] Presentazione dei lavori di LLDXG su Library science talk, 12-13 marzo 2012, http://www.nb.admin.ch/aktuelles/ausstellungen_und_veranstaltungen/00726/01611/03953/03958/index.html?lang=en
[62] Library Linked Data Incubator Group, Final Report, http://www.w3.org/2005/Incubator/lld/XGR-lld-20111025/; Library Linked Data Incubator Group: Use Cases, http://www.w3.org/2005/Incubator/lld/XGR-lld-usecase-20111025/
[63] World Wide Web Consortium (W3C), Use Cases, http://www.w3.org/2005/Incubator/lld/wiki/Use_Cases
[64] Library Linked Data Incubator Group, Charter, http://www.w3.org/2005/Incubator/lld/charter
[65] World Wide Web Consortium (W3C), Linked Library Data - CKAN MetaData Conventions, http://www.w3.org/wiki/TaskForces/CommunityProjects/LinkedLibraryData/Datasets/CKANmetainformation
[66] Library Linked Data, http://thedatahub.org/group/lld
[67] World Wide Web Consortium (W3C), Guidelines for Collecting Metadata on Linked Datasets in CKAN, http://www.w3.org/wiki/TaskForces/CommunityProjects/LinkingOpenData/DataSets/CKANmetainformation
[68] Library Linked Data Incubator Group, Datasets, Value Vocabularies, and Metadata Element Sets, http://www.w3.org/2005/Incubator/lld/XGR-lld-vocabdataset-20111025/
[69] NKOS, The 10th European Networked Knowledge Organisation Systems (NKOS) Workshop, https://www.comp.glam.ac.uk/pages/research/hypermedia/nkos/nkos2011/; Gordon Dunsire, Linked Data, Libraries and the Semantic Web cit.
[70] World Wide Web Consortium (W3C), Use Case Authority Data Enrichment, cit.
[71] Library Linked Data Incubator Group, Final Report. Appendix C: Semantic alignment, http://www.w3.org/2005/Incubator/lld/XGR-lld-20111025/#Semantic_alignment
[72] Gillian Byrne - Lisa Goddard, The Strongest Link: Libraries and Linked Data cit.
[73] Joab Jackson, Tim Berners-Lee: Machine-readable Web still a ways off, in: CGN, October 2009, http://gcn.com/articles/2009/10/30/berners-lee-semantic-web.aspx
[74] Linked Open Data Italia, Linked Open Data: dati aperti collegati e usabili, http://www.linkedopendata.it/
[75] Entro la British National Bibliography (BNB) pubblicata come LD dalla British Library vengono gestiti diversi namespace (MARC, VIAF, ISBD, DC, LCSH, Lexvo, GeoNames, http://thedatahub.org/it/dataset/bluk-bnb
[76] IFLA (Namespace Technical Group reposting to Committe on Standards); JSC for Development of RDA (DCMI/RDA Task Group, Dublin Core Metadata Initiative); DCMI Bibliographic Metadata Task Group (DCMI Vocabulary Management Community)
[77] «Libraries and librarians have a very high “trust” factor with the general public, and we are in a position to raise the general quality of the Semantic Web by ensuring Library data competing with data from the widest range of sources», Gordon Dunsire, Linked Data, Libraries and the Semantic Web cit.
[78] Vedi Tim Berners-Lee on the next Web in: TED (Technology, Entertainment, Design) conference http://www.ted.com/talks/tim_berners_lee_on_the_next_web.html
[79] Presentazione della conferenza SWIB12 Semantic Web in Libaries, 26-28 novembre 2012, http://swib.org/swib12/
[80] Carlo Bianchini, Il Library Linked Data Incubator Group e il futuro delle biblioteche, 2012, http://sites.google.com/site/homepagecarlobianchini/Ricerca/library-linked-data-e-il-futuro-delle-biblioteche
[81] Tim Berners-Lee, The 5 stars of open linked data, http://inkdroid.org/journal/2010/06/04/the-5-stars-of-open-linked-data/